工业企业欲彻底解决数据质量,唯有源端+末端综合数据治理

文章图片
文章图片
当下 , 数据治理的理念、书籍以及各种软文铺天盖地 , 仔细分辨大部分是基于DAMA或者DCMM相关理念基础 。无论是DAMA理论体系还是DCMM模型中数据治理的内容无外乎包括解决数据质量、数据安全、数据应用服务以及提升解决以上三个问题的能力 。
可以感觉到 , 所有人都已经深刻的认识到数据质量是数据治理中的核心所在 , 也是最难解决的问题 , 但大部分的理念、方案在解决数据质量方面相对传统且力度较浅 。
目前市面上主要存在以下两种数据治理模式 , 具体如下:
1) 源端数据治理 , 是指通过解决业务系统源头数据质量的问题 , 实现提高数据分析的准确率 。
2) 末端数据治理 , 是指针对解决数据全生命周期的末端(数据仓库层)数据质量的问题 , 实现提高数据分析的准确率 。
企业数据治理之源端模式
针对源端的数据治理是主流的数据治理模式 , 目前行业内80%以上的方案都是如此 。如静态数据治理、主数据管理、编码管理等 , 都是属于针对业务系统的直接影响实现数据质量的改造 , 最终达到支撑数据应用分析的目的 。
源端数据治理模式适用的企业 , 包括生产型企业、大型集团本部、运营管控型集团等的初步治理 。
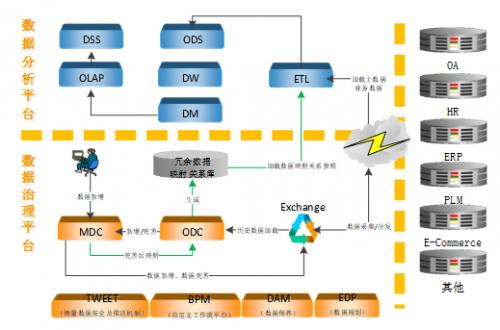
源端数据治理支撑数据分析及业务管理框架 , 具体如下图所示 。
文章图片
文章图片
图 源端数据治理支撑数据分析及业务管理
由上图可以看出 , 数据治理平台新增数据或者通过数据交换平台(Exchange)从业务系统采集数据进行规范、改造后 , 一方面冗余数据自动进入数据映射关系库 , 另一方面改造后的数据再次回传到对应业务系统实现对业务系统数据质量的改造(业务系统运行的前提下) 。
当ETL从业务系统中抽取数据的时候 , 同时从冗余数据映射关系库中抽取冗余数据的关系参照 , 在加载到数据仓库时会注明某些编码(数据)对应的业务实体对象其实是一个 , 这样未来进行数据分析时可以实现同一业务实体对象不同编码的业务数据的累加 , 从而最大化实现数据分析的精确度 。
企业数据治理之末端模式
关于末端的数据治理 , 目前存在的形式比较多 , 最传统的应该是借用ETL进行数据清洗的模式 , 这种模式基本都是结合数仓、BI的实施展开的 , 但是多年来的经验告诉我们效果非常之不理想 。因此 , 在AI技术刚刚萌芽之际 , 很多人把希望都寄托于AI技术能力挽狂澜 , 殊不知复杂的汉语环境更是让纯AI技术尴尬无比 , 比较典型的是数据中台中的AI技术进行数据质量的打通 , 结果一塌糊涂 。
综上所述 , 纯技术的手段几乎无法“撼动”数据质量这座大山 , 再高端的技术也不行 。
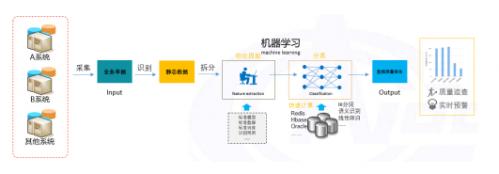
【工业企业欲彻底解决数据质量,唯有源端+末端综合数据治理】因此 , 多年的经验告诉我们 , 数据质量的识别除了需要各种技术之外 , 还需要有长期积累的模型、标准以及人的配合才行 , 具体如下图所示 。
文章图片
文章图片
图 数据质量识别的技术架构
长期的经验积累在数据治理行业非常重要 , 至少现阶段海量的标准模型、标准数据以及超前的理念可以最大程度的弥补AI技术的短板 , 可以让相关AI技术发挥到极致 , 具体细节不在此详述了 。
- 爱立信起诉苹果公司5g专利费用纠纷电信企业再次起诉
- 人类与AI如何共处?诺奖科学家、将棋天才、“低欲望社会”提出者的不同解答
- 2022首场工业数字化供需对接大会举办
- 九部门:严打平台企业超范围收集个人信息行为
- “亚洲锂都”积极推进“5G+工业互联网”赋能产业转型升级
- 中国百年矿业学府与智能工业新势力的完美结合
- 上市企业“海选”数字转型解决方案,这条“开放式创新”的路走对了
- 工信部公示工业互联网试点示范项目 浪潮云洲多个项目入围
- 签约!国内领军企业落户马鞍山
- 和数研究院被授予首批苏州工业园区“区块链重点企业”