搜索引擎技术之网络爬虫( 二 )
在真实的网络环境中 , 由于广告链接、作弊链接的存在 , 反向链接数不能完全等他我那个也的重要程度 。因此 , 搜索引擎往往考虑一些可靠的反向链接数 。
4)大站优先策略
对于待抓取URL队列中的所有网页 , 根据所属的网站进行分类 。对于待下载页面数多的网站 , 优先下载 。这个策略也因此叫做大站优先策略 。
5)其他搜索策略
一些比较常用的爬虫搜索侧率还包括PartialPageRank搜索策略(根据PageRank分值确定下一个抓取的URL)、OPIC搜索策略(也是一种重要性排序) 。最后必须要指明的一点是 , 我们可以根据自己的需求为网页的抓取间隔时间进行设定 , 这样我们就可以确保我们基本的一些大站或者活跃的站点内容不会被漏抓 。
3.网络爬虫更新策略
互联网是实时变化的 , 具有很强的动态性 。网页更新策略主要是决定何时更新之前已经下载过的页面 。常见的更新策略又以下三种:
1)历史参考策略
顾名思义 , 根据页面以往的历史更新数据 , 预测该页面未来何时会发生变化 。一般来说 , 是通过泊松过程进行建模进行预测 。
2)用户体验策略
【搜索引擎技术之网络爬虫】尽管搜索引擎针对于某个查询条件能够返回数量巨大的结果 , 但是用户往往只关注前几页结果 。因此 , 抓取系统可以优先更新那些现实在查询结果前几页中的网页 , 而后再更新那些后面的网页 。这种更新策略也是需要用到历史信息的 。用户体验策略保留网页的多个历史版本 , 并且根据过去每次内容变化对搜索质量的影响 , 得出一个平均值 , 用这个值作为决定何时重新抓取的依据 。
3)聚类抽样策略
前面提到的两种更新策略都有一个前提:需要网页的历史信息 。这样就存在两个问题:第一 , 系统要是为每个系统保存多个版本的历史信息 , 无疑增加了很多的系统负担;第二 , 要是新的网页完全没有历史信息 , 就无法确定更新策略 。
这种策略认为 , 网页具有很多属性 , 类似属性的网页 , 可以认为其更新频率也是类似的 。要计算某一个类别网页的更新频率 , 只需要对这一类网页抽样 , 以他们的更新周期作为整个类别的更新周期 。基本思路如图:

文章图片
文章图片
4.分布式抓取系统结构
一般来说 , 抓取系统需要面对的是整个互联网上数以亿计的网页 。单个抓取程序不可能完成这样的任务 。往往需要多个抓取程序一起来处理 。一般来说抓取系统往往是一个分布式的三层结构 。如图所示:
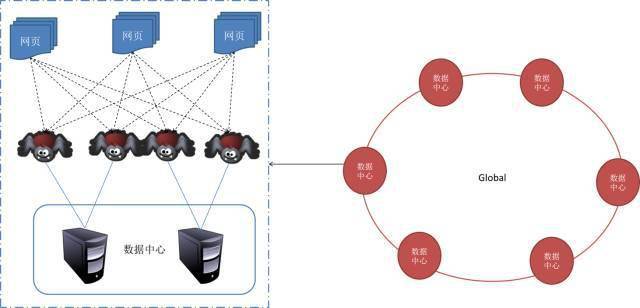
文章图片
文章图片
最下一层是分布在不同地理位置的数据中心 , 在每个数据中心里有若干台抓取服务器 , 而每台抓取服务器上可能部署了若干套爬虫程序 。这就构成了一个基本的分布式抓取系统 。
对于一个数据中心内的不同抓去服务器 , 协同工作的方式有几种:
1)主从式(Master-Slave)
主从式基本结构如图所示:
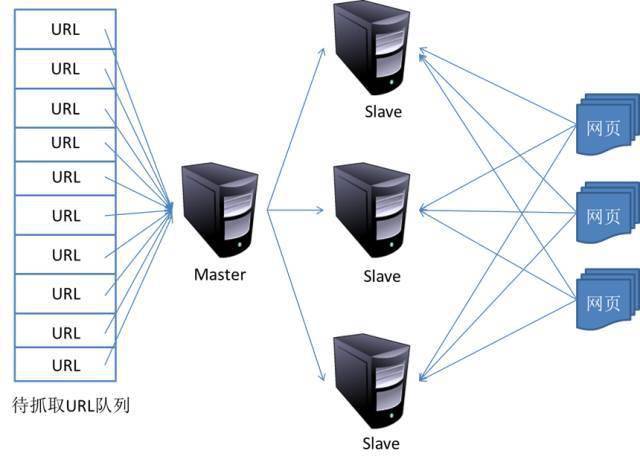
文章图片
文章图片
对于主从式而言 , 有一台专门的Master服务器来维护待抓取URL队列 , 它负责每次将URL分发到不同的Slave服务器 , 而Slave服务器则负责实际的网页下载工作 。Master服务器除了维护待抓取URL队列以及分发URL之外 , 还要负责调解各个Slave服务器的负载情况 。以免某些Slave服务器过于清闲或者劳累 。
- AI技术创新、模型创新、业务创新 全新服务模式助力金融机构数字化转型
- 云顶之弈龙族运营丧尸95阵容搭什么好(云顶之弈龙族运营丧尸95阵容搭配心得一览)
- 原神追忆之注连适合谁来用(原神追忆之注连适合角色分析)
- 复苏的魔女恐惧之馆怎么玩(复苏的魔女恐惧之馆玩法攻略大全)
- 明日之后夏尔资源战怎么打得高分(明日之后夏尔资源战高分打法解析)
- 原神绝缘之旗印适合哪些角色(原神充能圣遗物适用角色推荐)
- 崩坏3星火汇聚之时好玩吗(崩坏3星火汇聚之时活动详情一览)
- 克服天然缺陷!人工高效生物固氮技术潜力巨大
- 复苏的魔女异界之境奖励如何获得(复苏的魔女异界之境奖励领取途径分享)
- 另一个伊甸永恒之梦什么属性(另一个伊甸永恒之梦强度测评)