深度解析 | 柏科数据ISCloud分布式存储系统,多协议互通特性(一)
构建高性能计算HPC(High Performance Computing)集群可提升业务的运算速度(使其达到每秒万亿次级的计算速度) , 因此HPC被应用于解决大规模科学问题的计算和海量数据的处理 , 其中就包括科学研究、气象预报、计算模拟、军事研究、生物制药、基因测序等 。为保障文件、对象、大数据等多种格式数据 , 在HPC场景下 , 进行统一存储性能的高要求 , 这无疑是对传统数据存储方式发起了存储重构挑战 。

文章图片
文章图片
目前HPC应用正从过去的传统科研领域计算密集型 , 逐渐向新兴的大数据、人工智能以及深度学习等方向进行融合和演进 。继而 , 数字时代无论是智能制造、智慧医疗、智慧城市、智能家居 , HPC都将成为核心技术 。特别是近两年备受关注的人工智能领域 , 如自动驾驶汽车、无人机、人脸识别、医疗诊断以及金融分析和商业决策等 , 其核心是大数据支持 , HPC成为人工智能模型训练的重要支撑平台 。
HPC通过极快的处理速度 , 获取大量数据进行复杂的运算 , 实现数据即时分析 , 达到快速决策的目标 。因此 , HPC集群对于存储有着较高的性能要求 , 保证来自多个HPC服务器密集而多样的分析行为 。
同时 , 由于未分析的原始数据会越积越多 , 并且未来还会有更多的数据需要研究/处理 , 因此容量和扩展性也是重要的考虑因素 。HPC的总体数据最终会达到PB级别 , 需要超大的存储容量才能完成归档 。
在多样化的HPC场景下 , 日均产生的三维数据可达几百TB甚至PB级 , 因此 , 对存储性能有着更高的要求 。在海量数据的处理过程中 , 一次数据处理需要经过文件、对象、大数据等多种格式的数据处理 , 这无疑是对传统数据存储方式发起了巨大的重构挑战 。就“自动驾驶”、“石油勘探”场景为例 , 数据采集的原始数据是NFS格式 , 需要先转换为HDFS格式 , 才能利用大数据系统对数据进行预处理 , 最终将数据转换为NFS格式导入进人工智能训练集群及演练仿真集群, 对数据进行深度挖掘 , 进一步调整自动驾驶策略 。
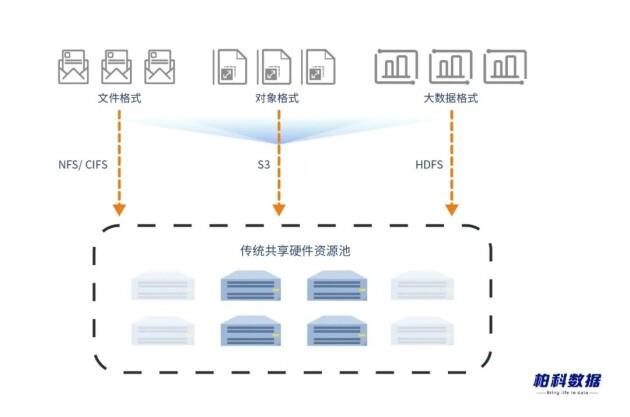
在整个数据处理闭环中 , 数据转换格式的时间占全过程的35%以上 , 如何提升多样性格式数据的处理效率 , 逐渐成为存储领域新型技术的主流趋势 。传统存储厂商仍通过共享硬件资源池 , 在一套硬件集群上划分出多了独立的逻辑资源池 , 分别部署对象、块、文件系统的存储池 , 实现硬件集群多样化格式的共享存储 。但在该资源池中 , 每一个逻辑资源池仅仅只会支持一种访问协议 , 对于跨协议访问时 , 仍需要先行拷贝原格式的原始数据 , 再将其进行数据格式转换 , 实现不同格式之间的数据相互转换及交互 。
在数据处理的过程中 , 数据拷贝产生的冗余副本不仅占用数据的存储空间 , 同时在数据格式转化的过程中 , 将会产生大量的数据丢失 。因此 , 传统的共享硬件资源池 , 仅能提高硬件资源的利用率 , 无法满足格式差异化要求及数据处理效率 , 以满足日均PB级的数据存储需求 。
文章图片
文章图片
? 共享硬件资源池 , 存储多个逻辑资源池
? 频繁跨协议访问 , 无法满足数据格式差异化处理效率
? 产生的冗余副本占用大量的存储空间
? 语义翻译过程中 , 存在数据丢失
柏科数据ISCloud分布式存储可采用多种协议互通技术 , 重构底层逻辑架构 , 部署统一的增值服务 , 语义抽象层 , 对多格式的非结构化数据进行统一管理 , 实现真正意义上的协议互通特性 , 来解决HPC场景下数据结构多样化的处理效率 , 满足日均PB级的数据存储需求 。
- 英雄联盟手游加里奥什么定位(英雄联盟手游加里奥属性强度解析)
- 航海王燃烧意志青年雷利技能什么效果(航海王燃烧意志青年雷利技能解析)
- 明日之后夏尔资源战怎么打得高分(明日之后夏尔资源战高分打法解析)
- 微信加别人的记录怎么查询(微信加别人的记录查看步骤解析)
- 伊甸园的骄傲冒险者修行问题怎么答(伊甸园的骄傲冒险者修行问答解析)
- 复苏的魔女装备词条怎么获取(复苏的魔女装备词条刷新技巧解析)
- 原神神铸定轨有什么用(原神神铸定轨作用解析)
- 永劫无间天海三排玩法有哪些(永劫无间天海三排打法技巧解析)
- 烟雨江湖孟翔武学选什么合适(烟雨江湖孟翔武学搭配方法解析)
- 2022支付宝随机福卡怎么领(2022支付宝随机福卡获取方法解析)