ICCV 2021 | 基于生成数据的人脸识别

文章图片
文章图片
作者 | 邱海波
编辑 | 王晔
本文是对发表于计算机视觉领域顶级会议ICCV 2021的论文“SynFace: Face Recognition with Synthetic Data” (基于生成数据的人脸识别)的解读 。

文章图片
文章图片
该论文由于京东探索研究院联合悉尼大学以及腾讯数据平台部完成 , 针对当前用来训练人脸识别模型的真实人脸数据存在隐私权限、标签噪声和长尾分布等问题 , 提出利用生成仿真的人脸数据来代替真实数据去对人脸模型进行训练 。文中通过引入Identity Mixup以及Domain Mixup极大地缩小了生成数据训练得到的模型与真实数据得到模型的准确率差距 , 并且系统性的分析了训练数据中各种特性对识别准确率的影响 。
论文链接:https://arxiv.org/abs/2108.079601研究背景近年来 , 人脸识别任务取得了巨大进展 , 其中大规模人脸训练数据集扮演了非常重要的角色 。但是由于近期来越发被重视的隐私问题 , 即人脸训练数据集的使用需要得到该数据集所包含的所有人的授权同意 , 部分大规模的数据集[1]已经从其官网下架 , 无法再访问 。另外这类从互联网上收集而来的数据集 , 还存在标签噪声以及长尾分布(即各个类别所包含的样本数量差距很大)等问题 , 如若没有妥善地去设计网络结构或者损失函数 , 那么必然带来识别准确率的下降 。再者这些数据没有人脸具体特性的标注(如表情 , 姿态 , 光照条件等) , 故而使得我们无法去系统性地分析这些因素在人脸识别里面的具体影响 。2探索分析
为了解决上述问题 , 我们准备引入生成数据代替真实数据来进行人脸识别模型的训练 。近些年来 , 基于GAN[2]的生成模型发展十分迅猛 , 其生成得到的人脸图片在某些场景下已经可以做到以假乱真的效果 , 参见图1 。

文章图片
文章图片
图1:第一行为真实人脸 , 第二行则是生成人脸
为了能进一步控制生成人脸的各种特性(如身份 , 表情 , 姿态和光照条件) , 我们采用了DiscoFaceGAN[3]作为基本的生成模型 , 先与真实数据训练得到的模型进行对比分析 。RealFace和SynFace分别代表利用真实和生成数据训练所得到的模型 , 然后在真实以及生成的测试集上进行评估 , 结果参见表1 。

文章图片
文章图片
表1:对真实以及生成数据训练得到模型进行交叉领域的评估结果
由实验结果我们可以发现 , 两者之间识别准确率的差距是由于真实数据与生成数据两种不同领域的差异造成 。通过进一步观察生成的人脸 , 我们发现同一类(即同一个人)中的样本人脸差异性较小 , 即类内距离较小 。我们利用MDS[4]可视化了真实数据与生成数据的深度特征 , 参见图2中绿色五边形以及青色三角形 。显而易见 , 生成数据的类内距离明显小于真实数据 。
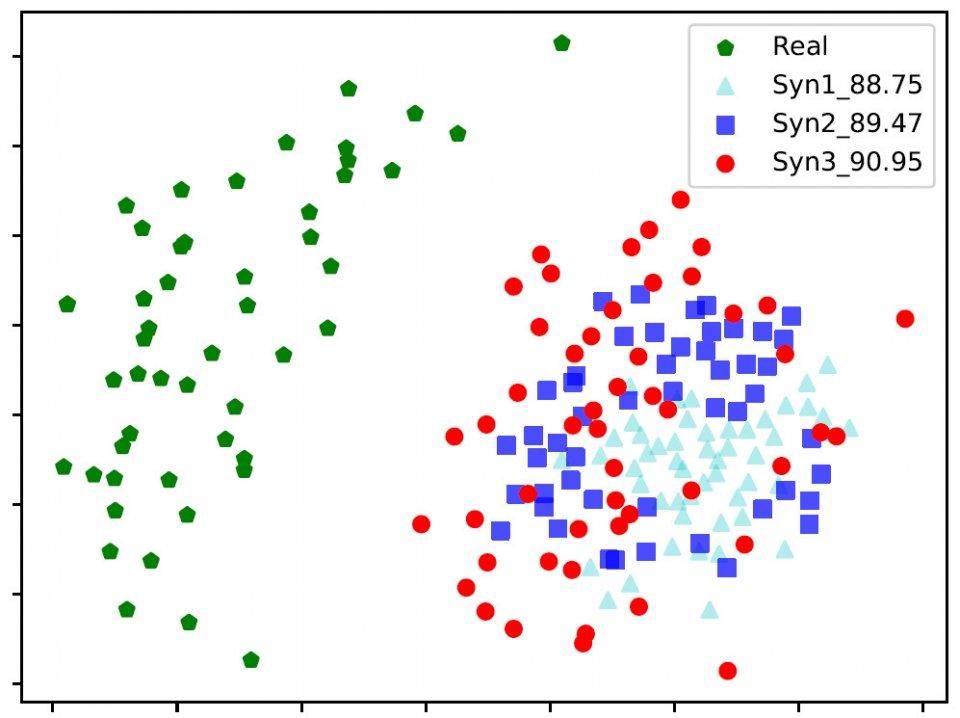
文章图片
文章图片
图2:真实数据以及三类不同生成数据的深度特征可视化3方法介绍
Identity Mixup (身份混合)为了增大生成数据的类内距离 , 受到Mixup[5]的启发 , 我们在生成人脸模型的身份系数空间引入mixup , 即Identity Mixup (IM) , 得到Mixup Face Generator 。对于两个身份系数和 , 我们得到其中间态(内插值)作为一个新身份系数 , 其对应的标签也随之线性改变 , 参见公式1 。另外我们通过可视化发现 , 如此得到的新身份系数同样能够生成高质量的人脸图片 , 而且其身份信息随着权重系数的变化 , 逐渐从一个身份变化到另一个身份 , 参见图3 。
- canalys公布2021年全球个人电脑市场数据
- oppo在2021年第三季度真无线耳机销量突破千万
- 2021年度中国互联网辟谣优秀作品即将发布
- 合众人寿江苏分公司荣获2021年度“最具社会责任品牌”称号
- Canalys:苹果2021年四季度重夺全球手机销量第一,小米第三
- 2021年度网友留言250个高频词!网上民声重磅发布
- 2021年这些中国CIO如何引领数字化转型?
- 2021第十六届金瑞营销奖重磅揭晓 双汇荣获最佳社会化营销奖
- 开创新气象,一图读懂重庆市人大2021
- 2021假日季智能手机哪家最吃香?苹果出货量重返第一宝座