语音识别系列 —— 特征部分(一)
语音本质是声带的振动 , 然后经过声道和口腔的调制才产生我们可以听到或拾取的声音 , 然而通过倒谱(cepstrum)分析语音就能将这一本质的特征参数提取出来 。
梅尔倒频谱(Mel-FrequencySpectrum,MFC)是一个可用来代表短期语音的频谱 , 其原理基于以非线性的梅尔刻度(melscale)表示的对数频谱及其线性余弦转换之上 。
梅尔倒谱系数(Mel-frequencycepstrumcoefficients,MFCC)是一组用来建立梅尔倒频谱的关键系数 , 对语音当中的片段 , 我们可以得到一组足以代表此语音的倒频谱 , 而梅尔倒频谱系数即是从这个倒频谱中推得的倒频谱(也就是频谱的频谱) 。与一般的倒频谱不同 , 梅尔倒频谱最大的特色在于梅尔倒频谱上的频带是均匀分布于梅尔刻度上的 , 也就是说 , 这样的频带会较一般我们所看到线性的倒频谱表示方法 , 和人类非线性的听觉系统(audiosystem)更为接近 。下面即使MFCC求取的步骤:

文章图片
文章图片
详细介绍如下:
1:预加重(Preempahsis):增加高频成分 , 使频谱光滑;
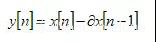
文章图片
文章图片
的取值是0.9~1之间 , 一般为0.98;一段正常的音频一般的低频成分比高频成分多 , 下面可以看出预加重对音频的影响:

文章图片
文章图片
2:加窗 , 分帧

文章图片
文章图片
如上图所示 , 音频信号为非平稳信号 , 一般采取分帧将其视为短时平稳信号处理 。为了保持连续性 , 一般会以半帧的长度为帧移 。窗函数常用的是矩形窗和汉明窗 , 这里无需再详细说明 。
3:短时傅里叶变换
学习信号的人都知道的一个时频转换 , 公式为:
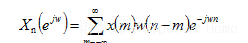
文章图片
文章图片
4:Mel频率
这一步我们将得到的线性频率转换为Mel频率 , 转换公式如下:
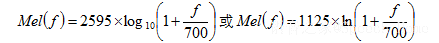
文章图片
文章图片
接下来在Mel频率轴构造M个三角带通滤波器组 , 且这M个三角滤波器在Mel频域尺度上是平均分布的 , 定义为:
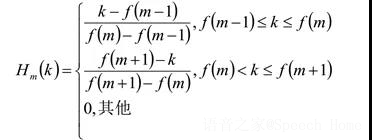
文章图片
文章图片
三角带通滤波器主要有两个目的:一是对频谱进行平滑 , 消除谐波的影响 , 突出原始语音的共振峰 , 因此 , 以MFCC为特征的语音识别系统并不会受到输入语音的音调不同而有所影响;二就是降低信息量 。
5:IDCT去相关
对上述每一个滤波器的输出计算其对数能量 , 并做离散余弦变换(DCT):
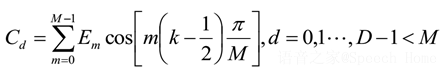
文章图片
文章图片
D为Mel倒谱系数的阶数 , 其不同分量对应不同的信息 , 实验表明最有用的语音信息包含在MFCC分量C1到C12之间 , 最有用的说话人信息包含子啊MFCC分量C6到C16之间 。
有时候会说到fbank特征 , 其实它跟MFCC的区别仅在于少做IDCT这一步 , 因为多维高斯函数要求每一维都是独立的 , 所以MFCC通过IDCT达到了去相关 , 如果DNN的输入那就只需要Fbank即可 。常说的39维MFCC如下:
12维倒谱系数+12维倒谱系数一阶差分+12维倒谱系数二阶差分+1维能量信息+1维能量一阶差分+1维能量二阶差分=39维MFCCfeature
- 网易游戏深耕未成年人网络保护领域积极探索人脸识别
- 和平精英|和平精英小团团语音包设置方法攻略一览
- Garmin epix 高端商务智能腕表、fēnix 7太阳能系列户外手表上市
- 和平精英小团团语音包怎么获得(小团团语音包获取方法介绍)
- 重庆联通数字化转型白皮书2.0今天发布:一系列惠民举措来了
- amd确定将为rx6000系列显卡换装更高速的gddr6显存
- 高德地图可莉语音导航怎么弄(高德地图可莉语音导航设置教程)
- 2022和平精英语音包在哪里设置(2022和平精英语音包更改流程)
- 微信重大更新!删除好友、语音暂停……这些功能终于来了
- 永劫无间小队怎么设置语音交流(永劫无间小队语音交流开启方法说明)