Cloudera Manager 术语和架构
为了有效地使用ClouderaManager , 您应该首先了解其术语 。
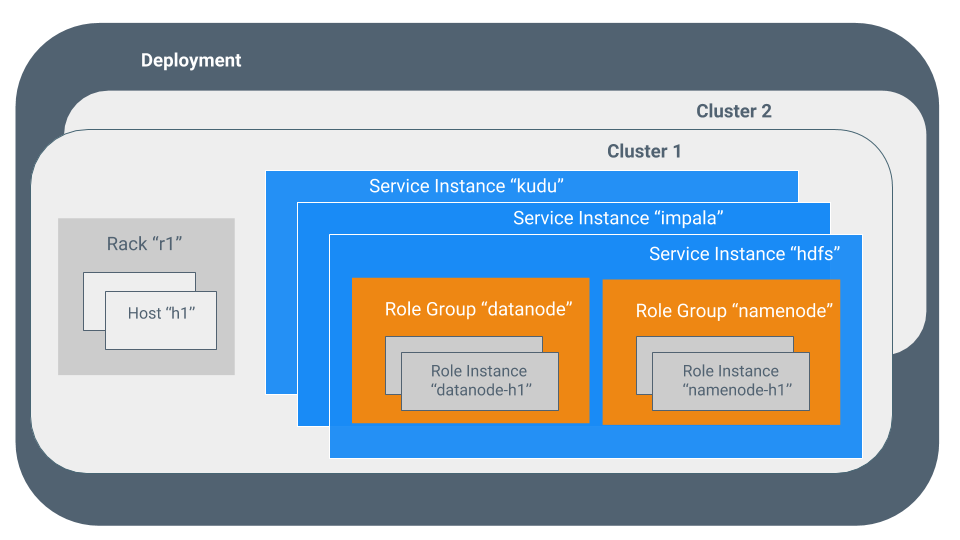
术语之间的关系如下所示 , 其定义如下:
文章图片
文章图片
【Cloudera Manager 术语和架构】有时 , 术语服务和角色用于同时指代类型和实例 , 这可能会造成混淆 。ClouderaManager和本节有时对类型和实例使用相同的术语 。例如 , ClouderaManager管理控制台的“主页”>“状态”选项卡和“集群”>“ClusterName”菜单列出了服务实例 。这类似于编程语言中的惯例 , 其中“字符串”一词可能表示类型(java.lang.String)或该类型的实例(“hithere”) 。在需要区分类型和实例的地方 , 单词“type”被附加以指示类型 , 而单词“instance”被附加以显式指示实例 。
部署
ClouderaManager及其管理的所有集群的配置 。
动态资源池
在ClouderaManager中 , 这是资源的命名配置 , 以及用于在池中运行的YARN应用程序或Impala查询之间调度资源的策略 。
集群包含HDFS文件系统并对该数据运行MapReduce和其他进程的一组计算机或计算机机架 。在ClouderaManager中 , 是一个逻辑实体 , 包含一组主机 , 在主机上安装的单个版本的ClouderaRuntime以及在主机上运行的服务和角色实例 。一台主机只能属于一个集群 。ClouderaManager可以管理多个集群 , 但是每个集群只能与一个ClouderaManagerServer关联 。
主机
在ClouderaManager中 , 是运行角色实例的物理或虚拟机 。一台主机只能属于一个集群 。
机架
在ClouderaManager中 , 是一个物理实体 , 包含一组通常由同一交换机提供服务的物理主机 。
服务在尽可能可预测的环境中运行在/etc/init.d/定义的SystemV初始化脚本的Linux命令 , 删除大多数环境变量并将当前工作目录设置为/ 。ClouderaManager中的托管功能类别 , 可以在集群中运行 , 有时称为服务类型 。例如:Hive、HBase、HDFS、YARN和Spark 。
服务实例
在ClouderaManager中 , 是在集群上运行的服务的实例 。例如:“HDFS-1”和“yarn” 。服务实例跨越许多角色实例 。
角色
在ClouderaManager中 , 服务中的功能类别 。例如 , HDFS服务具有以下角色:NameNode、SecondaryNameNode、DataNode和Balancer 。有时称为角色类型 。
角色实例
在ClouderaManager中 , 是在主机上运行的角色的实例 。它通常映射到Unix进程 。例如:“NameNode-h1”和“DataNode-h1” 。
角色组
在ClouderaManager中 , 这是一组角色实例的一组配置属性 。
主机模板
ClouderaManager中的一组角色组 。将模板应用于主机时 , 将创建每个角色组中的角色实例并将其分配给该主机 。
网关
一种角色类型 , 通常为客户端提供对特定群集服务的访问权限 。例如 , HDFS、Hive、Kafka、MapReduce、Solr和Spark各自具有网关角色 , 以为其客户提供对其各自服务的访问 。网关角色并非总是在其名称中带有“网关” , 也不是专门用于客户端访问 。例如 , HueKerberosTicketRenewer是一个网关角色 , 用于代理Kerberos中的票证 。
支持一个或多个网关角色的节点有时称为网关节点或边缘节点 , 在网络或云环境中常见“边缘”的概念 。对于Cloudera集群 , 当从ClouderaManager管理控制台的“操作”菜单中选择“部署客户端配置”时 , 群集中的网关节点将接收适当的客户端配置文件 。
Parcel
二进制分发格式 , 包含编译的代码和元信息 , 例如程序包描述、版本和依赖项 。
静态服务池
在ClouderaManager中 , 是跨一组服务的总群集资源(CPU , 内存和I/O权重)的静态分区 。ClouderaManager架构
- 云顶之弈同行指什么(云顶之弈同行术语解析)
- 关于社交平台中的谷圈术语
- 小鸡宝宝考考你,数学方程中的元次等术语是由谁创造的8月26日蚂蚁庄园答题
- 小鸡宝宝考考你,数学方程中的元次等术语是由谁创造的(蚂蚁庄园8月26日每日一题答案)
- Web3只是个营销术语?马斯克似乎明贬暗褒
- 【原创】零售行业首个数字化术语标准发布
- 公主连结n3h3是什么意思(公主连接简写术语黑话含义大全)
- Synaptics发布DisplayLinkManager测试版1.6
- 多多自走棋游戏有哪些术语
- 公主连接都有哪些游戏术语(游戏术语详情介绍)