深度神经网络是一种模拟人脑的神经网络以期能够实现类人工AI智能的机器学习技术 。人脑中的神经网络是一个非常复杂的组织 。成人的大脑中估计有1000亿个神经元之多 。
文章插图
图1 人脑神经网络

文章插图
图2 人脑神经网络回路扫描图
文章插图
图3 人脑神经网络回路扫描图
一、神经元1.生物神经元 一个神经元通常具有多个树突 。主要用来接受传入信息;而轴突只有一条 。轴突尾端有许多轴突末梢可以给其他多个神经元传递信息 。轴突末梢跟其他神经元的树突产生连接 。从而传递信号 。这个连接的位置在生物学上叫做“突触” 。
人脑中的神经元形状可以用下图做简单的说明:
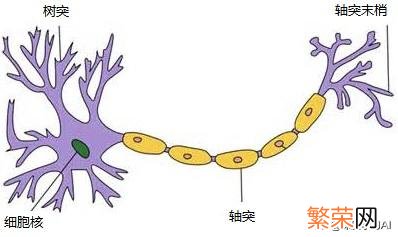
文章插图
图4 生物神经元
在生物神经网络中 。每个神经元与其他神经元相连接 。当它”兴奋”时就会向相连的神经元发送化学物质 。从而改变这些神经元内的电位;如果某个神经元内的电位超过了”阈值threshold”, 那么它就会被唤醒 。即”兴奋”起来 。向其他神经元发送化学物质 。
1943年 。心理学家McCulloch和数学家Pitts参考了生物神经元的结构 。发表了抽象的神经元模型MP 。
2. 神经元结构 (1)M-P神经元模型
M-P神经元模型是一个包含输入 。输出与计算功能的模型 。输入可以类比为神经元的树突 。而输出可以类比为神经元的轴突 。计算则可以类比为细胞核 。
注意中间的箭头线 。这些线称为“连接” 。每个上有一个“权值” 。
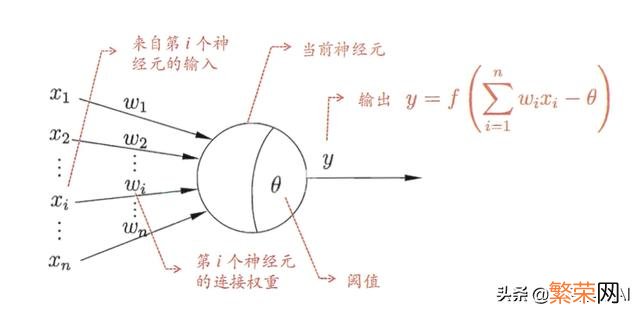
文章插图
图6 M-P神经元模型
在M-P神经元模型中 。神经元接收来自n个其他神经元传递过来的输入信号 。这些输入信号通过带权重(weight)的连接(Connection)进行传递 。神经元接接到的中输入值将与神经元的阀值进行比较然后通过”唤醒函数”(activation function)处理以产生神经元的输出 。
一个神经网络的锻炼算法就是让权重的值调整到最佳 。以使得整个网络的预测效果最好 。
(2)神经元结构:
输入:神经元的输入即特征 。X1, X2……Xn 即为输入的特征 。权重:神经元之间的连接即权重weight, 在神经网络锻炼的过程中 。不断的调节每个神经元连接的权重 。来使模型达到一个最优权重状态 。唤醒函数:神经元唤醒函数用于将输入特征值映射到输出值”0″和”1″, “1”对应于神经元兴奋 。”0″对应于神经元抑制 。常用的唤醒函数有:符合函数sgn, 对数S形函数sigmoid, 双曲正切S形函数tanh, ReLU, Softmax, Linear等 。唤醒函数较简单 。没有太多种类型 。阀值: 神经元是一个多输入单输出的非线性单元 。输入之和需要超过一定数值时(θ) 。输出才会有了一定的反应 。输出:神经元的输出可以看做是对所有输入特征值的一个预测结果 (3)神经元数学模型:
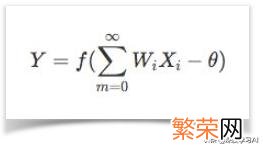
文章插图
神经元数学模型
一个神经网络可以看做是内含了许多参数的数学模型 。这个模型是若干个函数, 例如上式相互(嵌套)代入而得 。
二、单层神经网络(感知机)由两层神经元组成的神经网络 。称之为”感知机”(Perceptron), 输入层接收外面的世界信号后直接传输给输出层 。输出层是M-P神经元
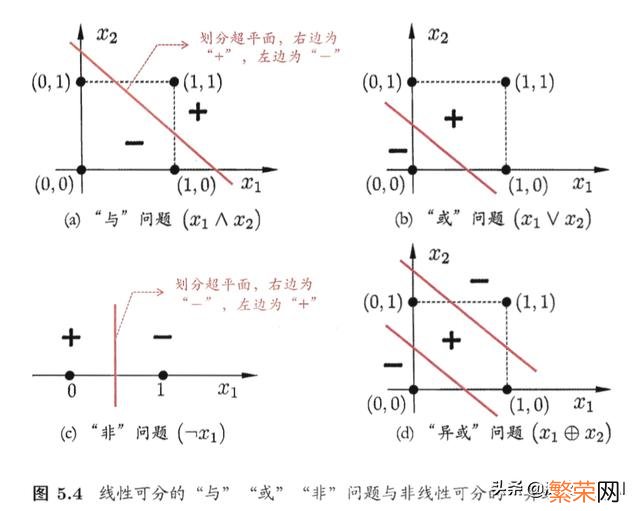
感知机能非常的容易的实现与 。或 。非运算 。解决线性分类问题 。
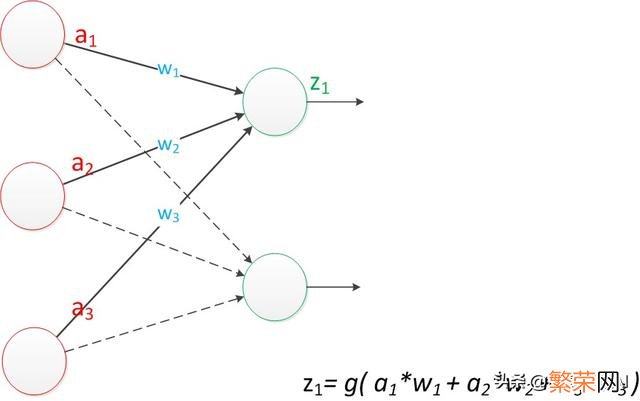
文章插图
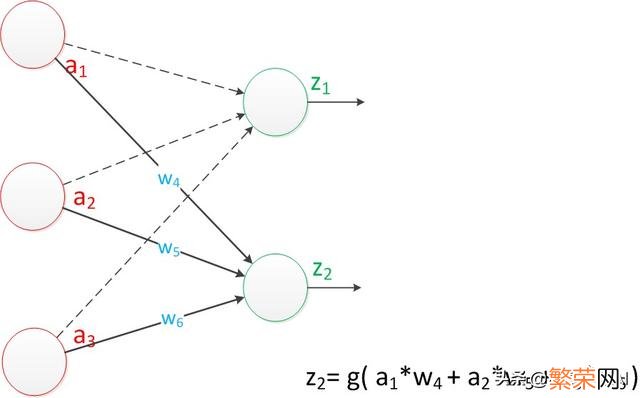
文章插图
单层神经网络—感知机模型
如果仔细看输出的计算公式 。会看到这两个公式就是线性代数方程组 。因此可以用矩阵乘法来表示这两个公式 。
例如 。输入的变量是[a1 。a2 。a3]T(代表由a1 。a2 。a3组成的列向量) 。用向量a来表示 。方程的左边是[z1 。z2]T 。用向量Z来表示 。
系数则是矩阵W(2行3列的矩阵 。排列形式与公式中的一样)
于是 。输出公式可以改写成:
g(W * a) = z;
这个公式就是神经网络中从前一层计算后一层的矩阵运算 。这也是目前大多数深度学习框架使用矩阵向量计算原因 。
感知机效果:与神经元模型不同 。感知器中的权值是通过锻炼得到的 。因此 。根据以前的知识咱们知道 。感知器差不多一个逻辑回归模型 。可以做线性分类任务, 但是无法做非线性分类任务:例如异或运算XOR 。同或XNOR运算.
文章插图
三、两层神经网络(多层感知机) 单层神经网络无法解决异或问题 。但是当增加一个计算层以后 。两层神经网络不仅可以解决异或问题 。而且具有非常好的非线性分类效果.
“多层感知机”:即在原来的单层神经网络基本上 。输入和输出层之间增加一层 。这一层称之为”隐层或隐藏层” 。隐层和输出层神经元都是拥有唤醒函数的功能神经元 。
1. 多层感知机结构 层级结构:每层神经元与下一层神经元全连接 。神经元之间不存在同层连接 。也不存在跨层连接
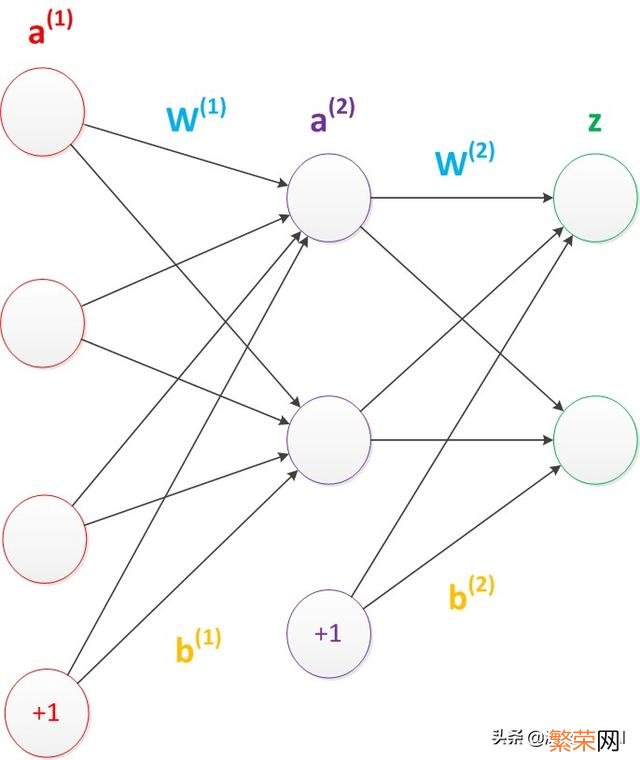
文章插图
多层感知机结构
上图中多层感知机结构图的中b偏置节点(bias unit) 。它本质上是一个只含有存放功能 。且存放值永远为1的单元 。在神经网络的每个层次中 。除了输出层以外 。都会含有这样一个偏置单元 。在考虑了偏置以后的一个神经网络的矩阵运算如下:(向量形式)
g(W(1) * a(1) + b(1)) = a(2);
g(W(2) * a(2) + b(2)) = z;
事实上 。神经网络的本质就是通过参数与唤醒函数来拟合特征与目标之间的真实函数关系
多层感知机效果:与单层神经网络不同 。理论证明 。两层神经网络可以没有极限逼近任意连续函数 。
面对复杂的非线性分类任务 。两层(带一个隐藏层)神经网络可以分类的很好 。
接下来就是一个例子(此两图来自colah的博客) 。红色的线与蓝色的线代表数据 。而红色位置和蓝色位置代表由神经网络划开的位置 。两者的分界线就是决策分界 。
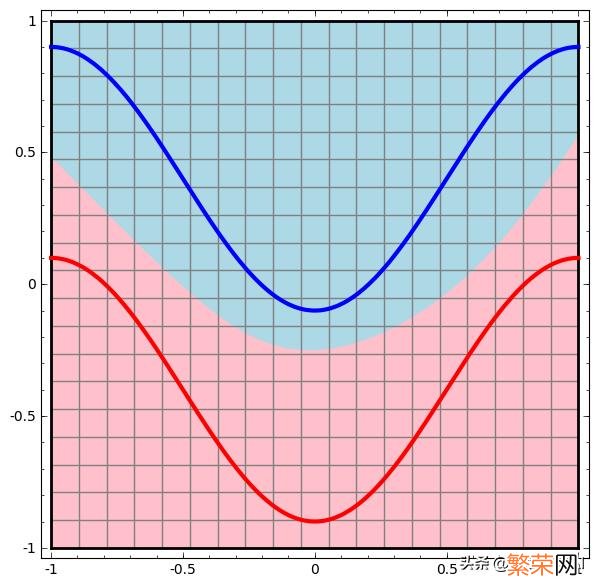
文章插图
两层神经网络(决策分界)
可以看到 。这个两层神经网络的决策分界是非常平滑的曲线 。而且分类的很好 。单层网络只能做线性分类任务 。而两层神经网络中的后一层也是线性分类层 。应该只能做线性分类任务 。为什么两个线性分类任务结合就可以做非线性分类任务?
咱们可以把输出层的决策分界单独拿出来看一下 。
就是下图
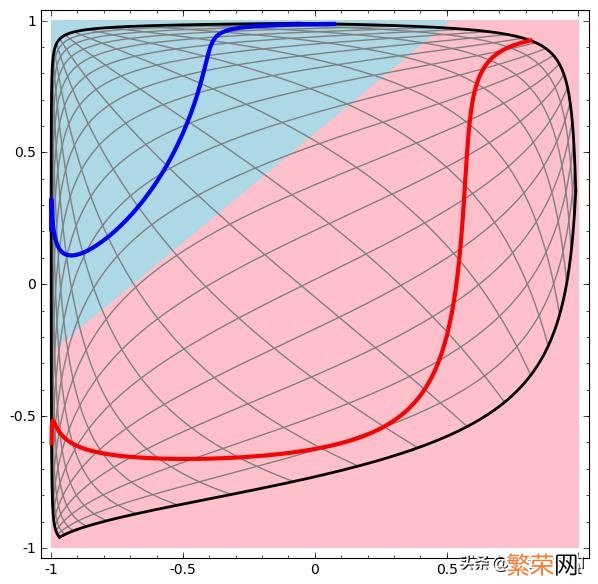
文章插图
两层神经网络(空间变换)
可以看到 。输出层的决策分界仍然是直线 。关键就是 。从输入层到隐藏层时 。数据发生了空间变换 。也就是说 。两层神经网络中 。隐藏层对原始的数据进行了一个空间变换 。使其可以被线性分类 。然后输出层的决策分界划出了一个线性分类分界线 。对其进行分类 。
这样就导出了两层神经网络可以做非线性分类的关键–隐藏层 。联想到咱们一开始推导出的矩阵公式 。咱们知道 。矩阵和向量相乘 。本质上就是对向量的坐标空间进行一个变换 。因此 。隐藏层的参数矩阵的作用就是使得数据的原始坐标空间从线性不可分 。转换成了线性可分 。
两层神经网络通过两层的线性模型模拟了数据内真实的非线性函数 。因此 。多层的神经网络的本质就是复杂函数拟合 。
2. 反向传播(Backpropagation 。BP)算法 由于多层感知机增加了隐层 。导致神经元数量和权重的增加 。如何计算和锻炼是个问题.
BP神经网络是这样一种神经网络模型 。它是由一个输入层、一个输出层和一个或多个隐层构成 。它的唤醒函数选用sigmoid函数 。选用BP算法锻炼的多层前馈神经网络 。
其算法基本思想为:在上面所述的多层感知机前馈网络中 。输入信号经输入层输入 。通过隐层计算由输出层输出 。输出值与标记值比较 。若有误差 。将误差反向由输出层向输入层传播 。在这个过程中 。利用梯度下降算法对神经元权值进行调整 。BP算法中核心的数学工具就是微积分的链式求导法则
前向(FP)和反向(BP)动图演示如下:
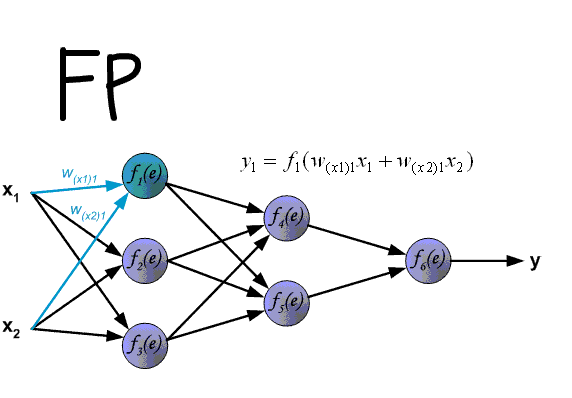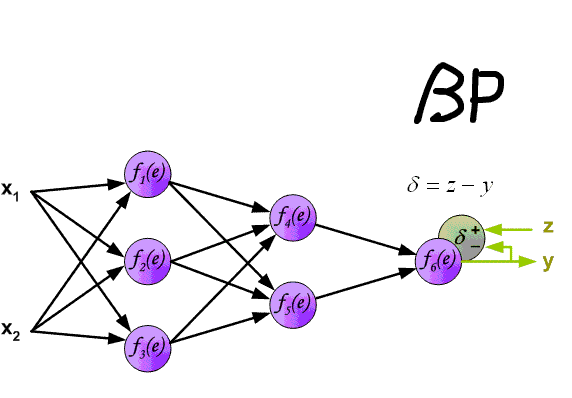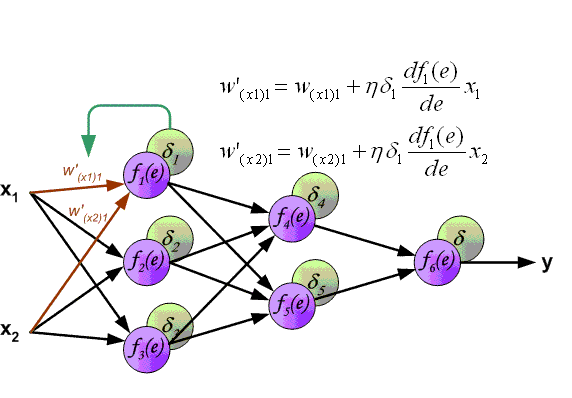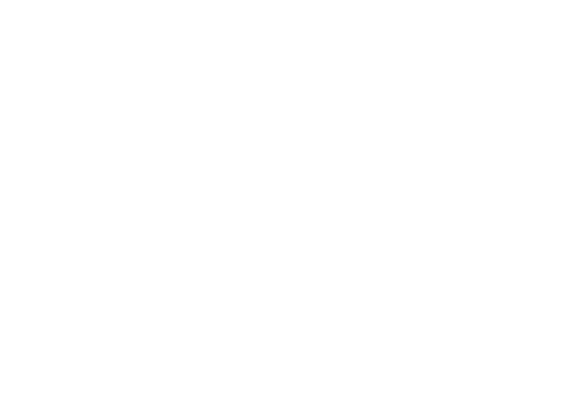
文章插图
缺点:
BP算法的缺点 。首当其冲就是局部极小值问题 。BP算法本质上是梯度下降 。而它所要优化的目标函数又非常复杂 。这使得BP算法效率低下 。四、多层神经网络(深度学习) 深度神经网络与感知机相比增加了更多的隐层 。以及更加复杂的网络结构 。与经典的锻炼方式不同 。深度神经网络有一个“预锻炼”(pre-training)的过程 。这可以方便的让神经网络中的权值找到一个接近最优解的值 。之后再使用“微调”(fine-tuning)技术来对整个网络进行优化锻炼 。这两个技术的使用大幅度减少了锻炼多层神经网络的期间 。
1.网络结构 :自动编码器: 自动编码器神经网络是一种无监督机器学习算法 。有三层的神经网络:输入层、隐藏层(编码层)和解码层 。该网络的目的是重构其输入 。使其隐藏层学习到该输入的良好表征 。其应用了反向传播 。可将目标值设置成与输入值相等 。自动编码器属于无监督预锻炼网络(Unsupervised Pretained Networks)的一种 。常用来预锻炼初始化网络权重 。限制波尔兹曼机(RBM):用来对数据进行编码提供给监督学习方法进行分类或者是回归 。另外就是得到权重矩阵和偏移量 。供BP神经网络初始化锻炼 。卷积神经网络CNN: 卷积神经网络在计算机视觉, 人脸识别 。物体检测 。图像分类, 图像分割 。风格迁移 。谷歌围棋AlphaGo等被广泛应用 。常用的网络结构有:AlexNet, GoogleNet, VGG, ResNet, DenseNet等 。以及这些网络结构的变种 。循环神经网络RNN 循环神经网络常被用于自然语言处理NLP 。机器翻译 。语音语义识别 。图像描述生成等 。例如:递归神经网络 。长短期记忆神经网络LSTM生成对抗网络GAN 用途:自然语言处理NLP, 图像处理 。图像生成等 。脉冲神经网络Spiking neural network:脉冲神经网络(SNN)属于第三代神经网络模型 。被誉为第三代人工神经网络 。实现了更高级的生物神经模拟水平 。除了神经元和突触状态之外 。SNN 还将期间概念纳入了其操作之中 。2. 效果 增加更多的层次有什么好处?更深入的表示特征 。以及更强的函数模拟能力 。
更深入的表示特征可以这样理解 。随着网络的层数增加 。每一层对于前一层次的抽象表示更深入 。在神经网络中 。每一层神经元学习到的是前一层神经元值的更抽象的表示 。例如第一个隐藏层学习到的是“边缘”的特征 。第二个隐藏层学习到的是由“边缘”组成的“形状”的特征 。第三个隐藏层学习到的是由“形状”组成的“图案”的特征 。最后的隐藏层学习到的是由“图案”组成的“目标”的特征 。通过抽取更抽象的特征来对事物进行区分 。从而获得更加好的区分与分类能力 。
五、锻炼过程选择数据集:根据锻炼任务的特征空间 。选择锻炼集和考证集 。测试集 。确定网络结构:根据锻炼任务的特征空间, 选择合适的网络结构:卷积层, 池化层, 归一化处理等 。预锻炼: 相关性预处理 。数据量预处理 。可以使用一些自动编码器等预锻炼方法来初始化网络权重和一些参数 。选择恰当的唤醒函数:sgn, sigmoid, tanh, ReLU, Softmax, Linear等 。唤醒函数每个都有自己的特性 。唤醒函数的选择会影响到网络的收敛速度和锻炼速度 。最终导致锻炼效果是否理想 。隐层单元和隐层的数量:隐层每层神经元网络结构 。神经元数量以及隐层的数量都不是固定的 。一般来探讨为了过滤出更多的特征信息 。通过增加隐层的数量 。模型会得到需求的灵活性和更多的特征信息 。例如:GoogLeNet, 2014年ILSVRC挑战赛冠军 。将Top5 的错误率降低到6.67%. 一个22层的深度网络(如果考虑pooling层是27层) 。有500万的参数量 。2012年 。AlexNet有8层 。但是它需要学习的参数有6000万个参数量 。权重初始化:权重初始化对于高效的收敛非常重要 。如果权重初始化为很大的数字 。那么唤醒函数会饱和(最底部位置), 导致死神经元(dead neurons) 。如果权重特别小 。梯度也会很小 。一般用小的随机数字初始化权重 。以打破不同单元间的对称性(symmetry), 最好是在中间位置选择权重 。均匀分布(uniform distribution )是比较好的选择 。调参:人工对部分经常可以看见超参数调参 。比如学习率、隐层数目 。选用随机搜索(random search)或者随机采样 。来选择最优超参数梯度下降:在机器学习算法中 。在最小化损失函数时 。可以通过梯度下降法来一步一步的迭代求解 。得到最小化的损失函数 。和模型参数值 。梯度下降相关介绍:监控 。特征图片生成等 。
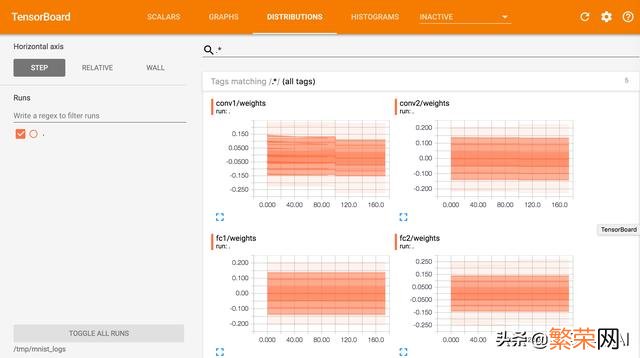
文章插图
(2)使用matplotlib图像处理库自己绘制
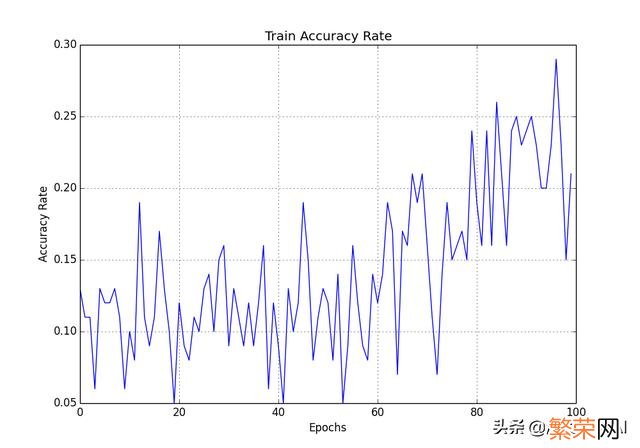
文章插图

文章插图
【详细介绍 神经元模型是一个包含什么的模型】过拟合: 即学习过度 。主要表现在两个方面: 第一 。在现有的锻炼数据上模型已经不能更加优化了 。但是整个学习过程仍然在学习; 第二 。对于局部数据噪声(noise)学习过度 。导致模型“颠簸” 。所谓对局部噪声学习过度表现在对于给定的锻炼数据 。模型过度学习了局部的噪声 。而这些噪声对于模型的泛化并没有实际用处 。六、云端锻炼平台百度云:/
- 2021中秋节的寓意是什么 2021中秋节的寓意介绍
- 一些常用的生活小妙招都有哪些 一些常用的生活小妙招介绍
- 腌萝卜怎么腌 腌萝卜的方法介绍
- 分享详细认证步骤 微信怎么实名认证步骤
- 毛笔的三种握笔方法 毛笔的三种握笔方法介绍
- 腊八节的风俗及寓意 有什么禁忌 腊八节的风俗介绍
- 大寒节气特点 大寒节气特点简单介绍
- 节气小寒大寒是什么意思 小寒大寒的意思介绍
- 理想之城角色介绍 理想之城简介
- 小寒节气介绍 小寒节气简单介绍