多元线性回归
具有多个特征的线性回归如果我们有一个具有多个特征的连续标记数据 。我们可以使用多元线性回归来建立机器学习模型 。
标签是数据的答案 。值是连续的 。以下面的房价示例 。标签是价格 。特征是大小 。卧室数量 。楼层数和房龄 。
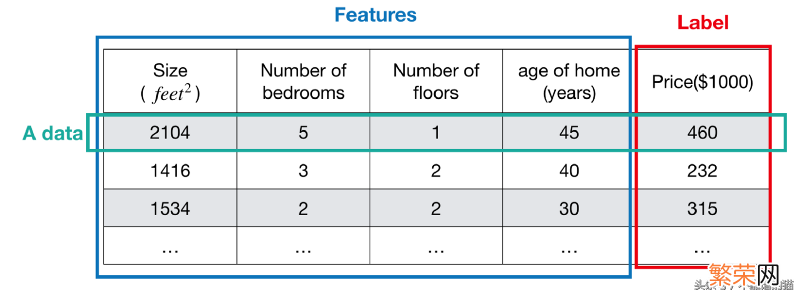
文章插图
文章插图
【均方误差计算例题 mse均方误差计算公式一般是多少】注意 。数据只有一个真正的机器学习模型 。不幸的是 。我们不知道真正的机器学习模型是什么 。为了找到真正的模型 。我们做了一个假设 。调整它直到我们可以检查它是否足够接近真实的模型或者它是错误的(根据准确率 。精度 。F1分数等标准) 。如果这个假设是错的 。那么再做一个调整 。
在选择机器学习模型时 。一定要注意假设 。
根据以上房价的例子 。假设数据的真实模型是线性的 。那么我们可以尝试使用线性回归及其假设函数 。
假设函数
在多元线性回归中 。具有多个变量x和参数θ的假设函数如下所示 。
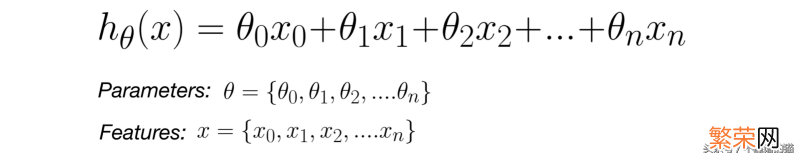
文章插图
文章插图
以下示例显示了如何使用假设函数 。
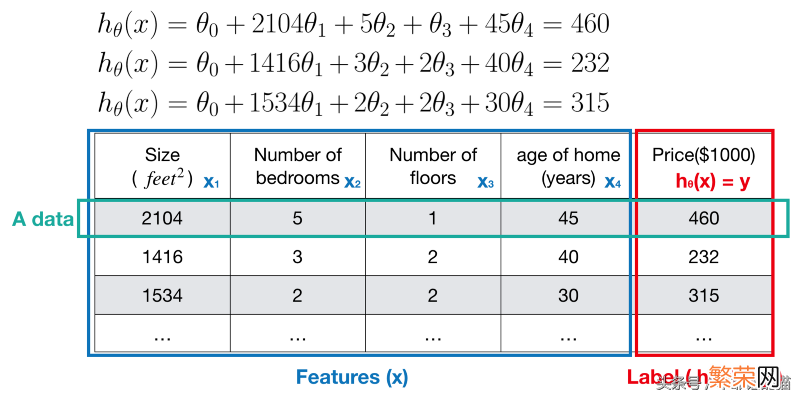
文章插图
文章插图
在调整假设时 。我们的模型学习参数θ 。这使得假设函数h(x)成为“好的”预测器 。一个好的预测器意味着假设对真实模型足够接近 。越接近越好 。
但是 。我们如何知道假设h(x)是否足够好?答案是使用成本函数 。我们定义该成本函数来衡量假设的误差 。
成本函数
假设函数 h(x) 的准确性可以使用成本函数来度量 。在回归问题中 。最常用的代价函数是均方误差(MSE) 。公式定义如下 。
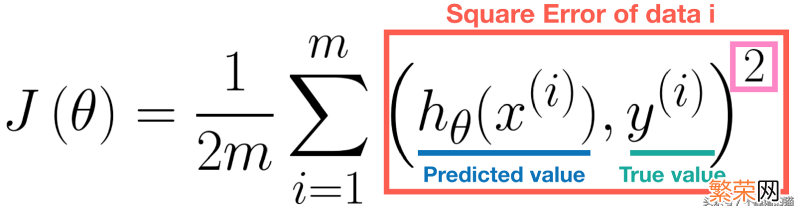
文章插图
文章插图
注意 。正方形(参见上面的粉色矩形)是必要的 。因为误差值总是正的 。此外 。平方误差函数是可微的 。因此我们可以对其应用梯度下降法 。
从本质上讲,成本函数J(θ)是每个数据的平方误差的总和 。误差越大 。假设的性能越差 。因此,我们要减少误差,即最小化J(θ) 。
梯度下降算法
梯度下降算法是最小化成本函数的常用方法 。一旦找到最小误差 。机器学习模型同时学习最佳参数θ 。因此 。我们可能会找到好的预测器 。一个具有最佳参数θ的假设函数 。它可以产生最小误差 。
请注意 。我们在这里使用“可能”这个词 。因为具有最佳参数θ的假设可能会遇到问题 。即所谓的“过度拟合” 。
- 伪代码
在每次迭代时 。需要同时更新 参数θ。
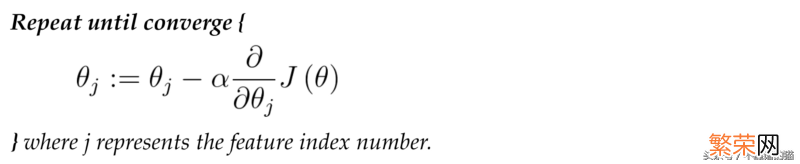
文章插图
文章插图
为了更好的理解梯度下降算法 。我们将如下图所示的步骤可视化 。
在图(a)中,起点是橙色(θj J(θj)) 。计算其偏微分法,然后乘以一个学习率α和更新后的结果是绿色(θj J(θj)),如图(b)所示 。

文章插图
文章插图
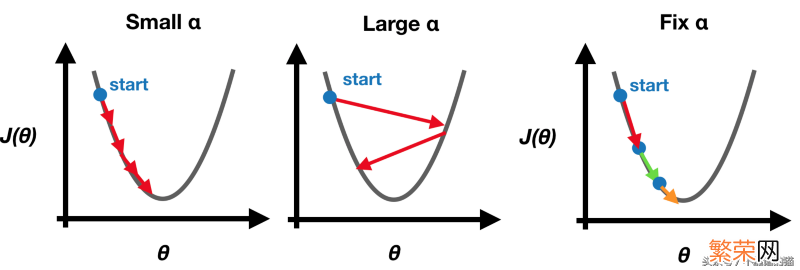
- 学习率α
请注意 。我们在开始时设置固定学习率α 。因为梯度下降将缓慢且自动更新 。直到达到最小值 。因此 。不需要在每次迭代时自己改变学习率α 。
文章插图
文章插图
在这一部分 。我们提供两种技能 。即特征缩放和学习率 。以确保梯度下降能够很好地发挥作用 。
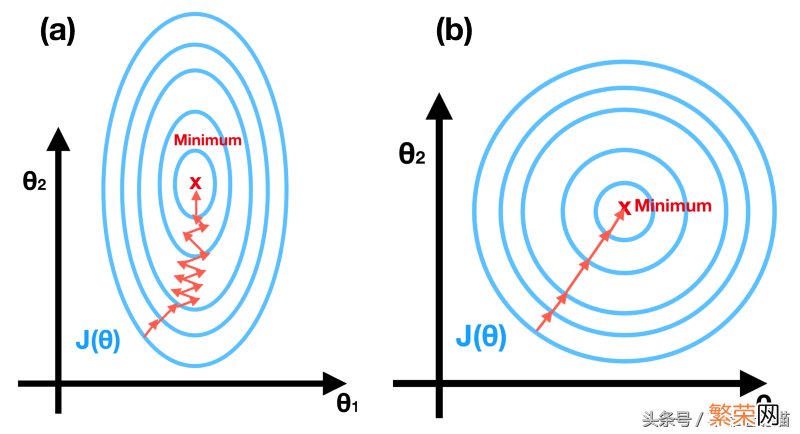
特征缩放 。也称为归一化特征 。由于每个特征的不同范围 。contours可能非常粗糙 。这将使梯度下降极度缓慢 。见图(a) 。在特征缩放之后 。结果显示在图(b)中 。
值得确保的是 。这些特性在相似的范围内 。并且大致在[- 1,1]范围内 。
文章插图
文章插图
缩放特征的一种方法是均值归一化 。公式为
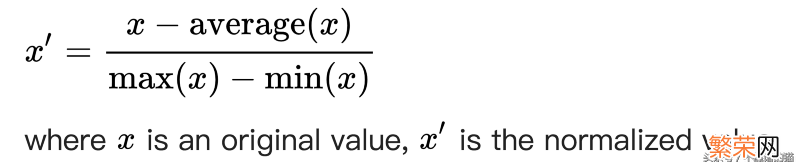
文章插图
文章插图
学习率α -如何选择α的值?建议试试…… 。0.001,0.003 。… 。0.01,0.03 。… 。0.1,0.3 。… 。1 。……
正规方程法在求解线性回归问题时 。正规方程法非常有用 。
举一个简单的例子 – 单变量的线性回归 。在下图中 。有三个线性方程 。因为我们有三个数据 。

文章插图
文章插图
在线性代数中 。线性系统可以表示为矩阵方程 。
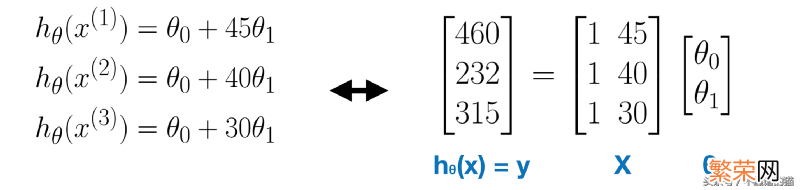
文章插图
文章插图
如果您熟悉线性代数中的伪逆的概念 。则可以通过以下公式获得参数θ:
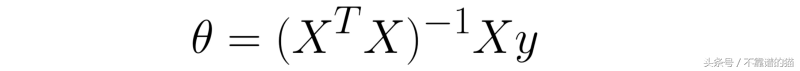
文章插图
文章插图
在多元线性回归中 。公式与上述相同 。但是 。如果正规方程是不可逆的怎么办?然后考虑删除冗余特征或使用正则化 。
总之 。使用正规方程的优点是
- 无需选择学习率α
- 无需迭代
- 特征缩放不是必需的
- 物理降温最佳方法是什么 给宝宝物理降温最正确的方法
- 上课瘦腿的方法 上课瘦腿的方法推荐
- 大公仔怎么洗 大公仔清洗方法
- 常用的茶叶储存方法 茶叶有哪些储存方法
- 白砂糖红糖储存方法 白砂糖红糖如何保存
- 鲜母乳储存方法 鲜母乳储存方法是什么
- 储存小米的保鲜方法 小米如何存放
- 紫薯红薯的储存方法 紫薯红薯如何保存
- 储存冬瓜方法 储存冬瓜方法是什么
- 储存大虾方法 储存大虾方法是什么