冯·诺依曼架构下的存内计算
怎样才能让一枚芯片拥有更高的性能?
大多数人的回答一定是紧跟摩尔定律 , 在同样大小的芯片空间内装进更多的晶体管 , 其手段无外乎更先进的制程(从7nm到5nm)以及更先进的封装方式(如chiplet) 。
然而 , 随着先进制程逼近1nm的物理极限 , 摩尔定律不可避免的放缓 , 即便是在日常生活中 , 人们也能感受到手机Soc、电脑的CPU的升级换代效果越来越差 , 从过去的每代提升40%性能迅速下降至20%甚至10% 。
与之对应的是 , 当今社会对数据、算力、芯片性能的要求却越来越高 , 整个下游市场既然有庞大的需求出现 , 那么整个产业链的各方都在想方设法来提高芯片的性能 , 既然传统的在晶圆上改进工艺的方式进展缓慢 , 那么在更上层的计算机架构上动刀或许会有意想不到的收获 。
今年以来 , 一些跳出传统计算机结构体系的设想正在转为研究成果出现在各大顶级期刊上 , 它就是“存内计算” 。
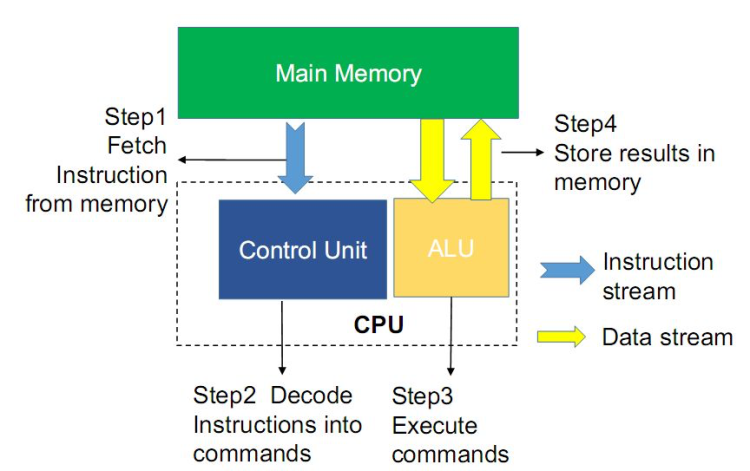
存内计算 , 顾名思义就是把计算单元嵌入到内存当中 。通常计算机运行的冯·诺依曼体系包括存储单元和计算单元两部分 , 计算机实施运算需要先把数据存入主存储器 , 再按顺序从主存储器中取出指令 , 一条一条的执行 , 数据需要在处理器与存储器之间进行频繁迁移 , 如果内存的传输速度跟不上CPU的性能 , 就会导致计算能力受到限制 , 即“内存墙”出现 , 例如 , CPU处理运算一道指令的耗时假若为1ns , 但内存读取传输该指令的耗时可能就已达到10ns , 严重影响了CPU的运行处理速度 。
此外 , 读写一次内存的数据能量比计算一次数据的能量多消耗几百倍 , 也就是“功耗墙”的存在 。2018年 , 谷歌针对自家产品(Chome/TensorflowMobile/videoplayback/videocapture)的耗能情况做了一项研究 , 发现整个系统耗能的62.7%浪费在CPU和内存的读写传输上 , 传统冯·诺依曼架构导致的高延迟和高耗能的问题成为急需解决的问题 , 其中的短板存储器成为了制约数据处理速度提高的主要瓶颈 。
文章图片
文章图片
【冯·诺依曼架构下的存内计算】冯·诺依曼架构图
把计算单元嵌入到内存当中的理想情况下 , 存内计算可以有效消除存储单元与计算单元之间的数据传输耗能过高、速度有限的情况 , 从而有效解决冯诺依曼瓶颈 。
存内计算的概念早就有迹可循 , 在上世纪70年代WilliamH.Kautz就曾提出过存储和逻辑整合的方案 , HaroldS.Stone紧接着发表了支持逻辑运算的存储计算结构 , 但由于当时的性能瓶颈问题不算突出 , 处理器的发展暂能满足数据处理的需求 , 因而学界、业界并没有对该领域投入过多关注 。
如今 , 随着人工智能技术的发展 , AI在各领域的应用逐渐广泛 , 以深度学习为代表的神经网络算法需要系统能高效处理海量的非结构化数据 , 例如文本、视频、图像、语音等 , 这导致在冯·诺伊曼架构下的硬件需要频繁读写内存 , 其计算任务有着并行运算量大、参数多的特点 , 这使得AI芯片对并行运算、低延迟、带宽等有着更高的要求 , 也因此 , 存内计算在人工智能时代迎来了发展的黄金时期 。
存内计算的热度肉眼可见的在各大学术会议上发酵 。2018年的IEEE国际固态电路会议(ISSCC)专门用了一个议程来研讨存内计算相关话题;到2019年 , 电子器件领域的顶级会议IEDM上关于存内计算的研讨议程则变成了三个 , 相关论文也达到二十余篇;2020年的ISSCC上存内计算的论文也上升至七篇 。
- 古尔曼爆料苹果将发布macstudio、ios显示器
- 古尔曼:苹果明日将发布“macstudio”
- 科技以人为尊 欧曼银河在海南文昌“航天城”上市
- 缺乏电源性质符号等标识纽曼召回80个耳机
- 英雄降临·与光同行|青蛙王子&奥特曼联名系列洗沐重磅上市
- 黎明觉醒罗曼好感怎么提升(黎明觉醒手游罗曼送礼攻略)
- 鬼泣巅峰之战尼曼怎么玩(鬼泣巅峰之战尼曼boss打法心得一览)
- 文明与征服查理曼大帝阵容搭什么好(文明与征服查理曼大帝阵容组合方案分享)
- 古尔曼:苹果下一款外接显示器“可能”在来年推出
- 计算神经科学家、IMAGEN之父冈特·舒曼已全职加盟复旦