全球IT需求大爆发的机会,Intel才不会浪费( 三 )
分别是:
1、专用于高性能深度学习AI训练的HabanaGaudi2处理器和GrecoAI加速器;
2、英特尔数据中心显卡(代号ArcticSound-M);
3、第四代英特尔?至强?可扩展处理器(代号SapphireRapids)的部分细节;
4、以及英特尔基础设施处理器(IPU)的路线图(发展规划) 。
这4种硬件 , 覆盖了IPU、CPU、GPU、AI处理器;应用场景也覆盖了从云到边缘再到终端 。

文章图片
文章图片
英特尔HabanaGaudi2深度学习训练处理器
首先是可用于数据中心和云的两款AI产品“HabanaGaudi2AI深度学习训练处理器”和GrecoAI加速器 , HabanaGaudi2在处理器本身规格升级的基础上 , 通过应用更先进的7nm制程和配置96GB高速存储 , 同时板载SRAM从24MB增加到48MB , 相比上一代产品性能提升十分明显 , 可针对计算机视觉与自然语言处理的模型训练与推理提供更高效能 , 并解决客户最关注的两个问题:降低服务器处理成本 , 还能减少训练模型所需时间 。
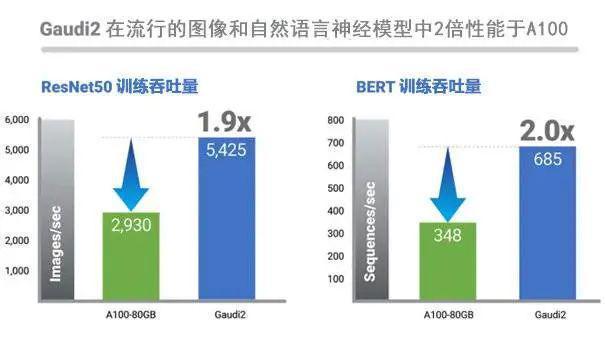
文章图片
文章图片
此前英特尔就曾和宾夕法尼亚大学医学院联合开发了一项技术 , 通过应用联邦学习算法 , 帮助包括宾夕法尼亚大学在内的29个国际医疗机构在保护患者隐私的情况下 , 利用各方拥有的脑瘤数据共同训练神经模型 。随着Gaudi2的加入 , 人工智能在医疗方面的应用也必然会进一步加速 , 从而帮助人们解决更多实际医疗需求 。
GrecoAI加速器的亮点则在于对于AI推理应用场景的专门优化 , 通过应用更先进的半导体制程 , 将功耗降到了75W , 让搭载GrecoAI加速器的加速卡更利于在服务器中进行使用 。纵观目前全球的AI处理器发展进度 , 英特尔这两款处理器的计算能力与能效表现 , 在整个行业中都是非常出色的 。
然后是全新的数据中心CPU和GPU 。代号为SapphireRapids的第四代英特尔?至强?可扩展处理器已经正式开始出货 。通过支持DDR5、PCIe5.0和CXL1.1 , 并凭借全新的集成加速器以及对AI工作负载的软硬件优化 , 第四代英特尔?至强?可扩展处理器相较上一代实现了显著的性能提升 。例如 , 它集成的英特尔通信加速技术 , 有助于提升吞吐量;采用的英特尔数据流加速器 , 能够支持更高效的数据移动 , 包括从云平台到边缘的移动 。
SapphireRapids还针对电信网络做了专门的优化 , 可以为虚拟无线接入网(vRAN)部署提供高达2倍的容量增益 。同时 , 其内置高宽带内存(HBM) , 将显著提高处理器的可用内存带宽 , 为高性能计算提供强劲动力 。
美国阿贡国家实验室超级计算机“Aurora”
英特尔通过合作 , 帮助企业充分利用至强处理器及软硬件产品组合 , 构建优化的解决方案 。如大会上的展示 , 第四代英特尔?至强?可扩展处理器还与英特尔此前发布的数据中心显卡PonteVecchio一起 , 成为了美国阿贡国家实验室超级计算机“Aurora”(极光)的核心架构 。通过强劲的CPU和GPU组合 , 后者整体算力已经超过2Eflop 。
数据中心GPU显卡“ArcticSound-M”
全新的面向多媒体转码、视觉图形处理和云端推理的英特尔数据中心GPU显卡“ArcticSound-M” , 能够提供每秒150万亿次运算 , 将包含两种不同的配置 , 150W功率版本和75W功率版本 , 分别封装了32个和16个Xe内核 。这两种配置均配备了4个Xe媒体引擎、英特尔首款面向数据中心的AV1硬件编码器和加速器、GDDR6内存、光线追踪单元和内置XMXAI加速 。可以实现处理多达8路4K视频流或超过30路1080p视频流转码 , 支持40路以上高清分辨率游戏 , 62个远程桌面 , 从而支持包括直播推流、云游戏、虚拟机、AI加速在内的多种用途应用 。
- amd发布全球首发5nm处理器锐龙7000
- 哔哩哔哩大规模「毕业」,涉及游戏等多个业务部门
- 光遇5.24每日任务怎么做2022(光遇2022年5月24日大蜡烛位置)
- 支付宝蚂蚁庄园2022年5月25日答案最新(支付宝蚂蚁庄园2022年5月25日答案大全)
- “每满生活”为大家带来了这些爆款伞
- 打工生活模拟器攻略大全(打工生活模拟器下棋攻略)
- 永劫无间武田信忠修行任务攻略大全(武田信忠命定之人解锁攻略)
- 校园不准恋爱游戏攻略(全关卡通关攻略大全)
- 割草的100种方式攻略大全(新手入门游戏攻略)
- 割草的100种方式兑换码大全(2022最新礼包兑换码分享)