字节跳动音乐检索系统bytecover2入选( 二 )
3、特征降维模块(PCA-FC)
通过测算 , 团队发现工业级别的翻唱系统大部分耗时集中在特征检索阶段 , 而这一阶段的时间消耗基本和曲库的大小以及特征向量的尺寸线性相关 。曲库中歌曲的数目会随着业务的增长而不断增加 , 因此降低特征向量尺寸成为优化检索系统整体耗时的必由之路 , 而同期其他翻唱向量特征降维的工作往往采用一个全连接层来将高维向量投影到维度更低的空间 。
实验结果发现 , 单纯使用全连接层进行降维会明显降低系统的检索能力 , 团队认为这种现象不仅是因为更小的尺寸限制了向量的表征能力 , 性能的损失也来自于随机初始化的全连接层对特征各向同性的破坏 。
随后对数据可视化之后可发现 , 降维后特征分布在一个锥形空间 , 表现出明显的各向异性 , 此种性质不利于使用余弦距离为度量的向量检索 。
因此团队尝试使用PCA对特征向量进行降维操作并随后用PCA的变换矩阵初始化一个全连接层 , 把该层和特征提取网络连接进来并联合训练 , 并将模块称作PCA-FC 。
实验结果显示 , PCA-FC能显著提升降维模型的检索性能 , 在保持检索性能不变的前提下向量尺寸可以被压缩8倍 。
文章图片
文章图片
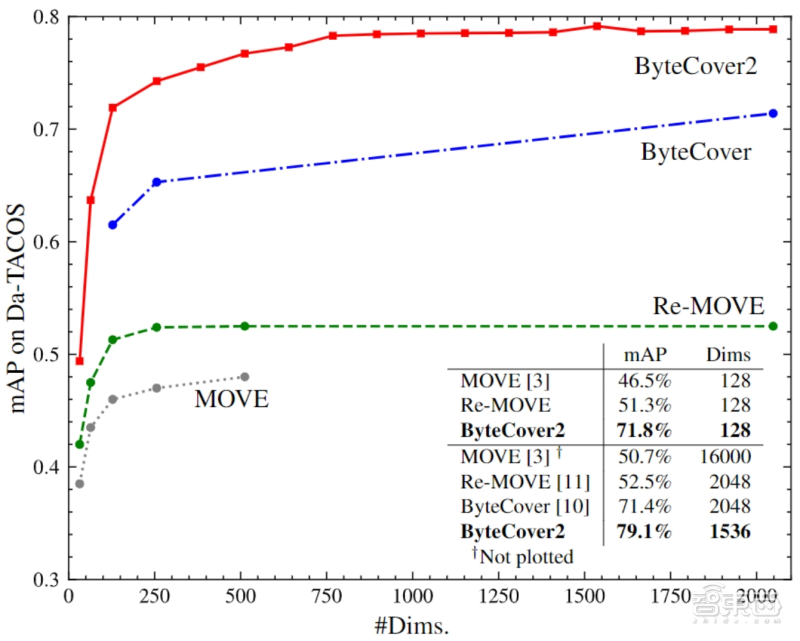
▲对比结果
从结果来看 , 一直以来Da-Tacos是作为评估翻唱识别的基准测试数据集 , 在该数据集上 , 采用1536维的ByteCover2模型取得了远超其他方案的SoTA性能 , 全类平均正确率指标(mAP)达到79.1% , 而ByteCover系列以外的最好方法Re-MOVE的该项指标只有52.5% 。
值得一提的是 , 128维的ByteCover2模型甚至超过了2048维的ByteCover1和Re-MOVE方法 。
此外 , ByteCover1系统还参加了2020国际音频检索评测大赛MIREX , 过程中大幅刷新了翻唱识别赛道历年最好记录 , mAP指标达到84% , 是同年参加该竞赛的其他方案性能的14倍 。

文章图片
文章图片
二、智能音乐:提高挑选音乐片段效率 , 创新自监督音乐预训练算法
在智能音乐方向 , 字节跳动火山语音团队基于Transformer的声音事件检测模型HTS-AT、基于层级式Transformer的自监督音乐预训练算法S3T两篇论文均被ICASSP2022收录 。
1、HTS-AT:用于声音分类和检测的分层标记语义音频
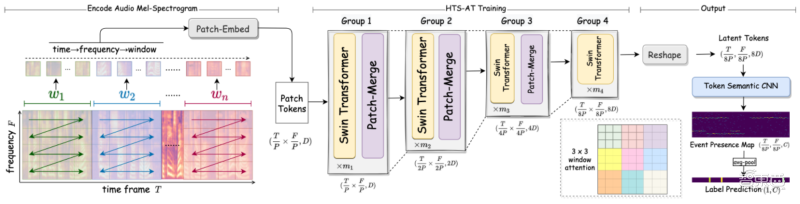
HTS-AT针对音频任务的特性 , 该结构能有效提高音频频谱信息在深度Transformer网络中的流动效率 , 提高了模型对声音事件的判别能力 , 并且通过降低输出特征图的大小 , 显著降低了模型地计算量与内存消耗 。HTS-AT还引入了TokenSemantic模块 , 使模型具备预测声音时间起始与终止点的能力 , 并且无需使用额外有标注数据进行训练 。
文章图片
文章图片
▲HTS-AT模型的结构
综合以上技术 , HTS-AT在标准数据集AudioSet上的mAP指标达到0.471 , 是当前的该数据集上的最佳水平 , 且参数与计算量都小于之前的最佳方法;另外 , 在声音事件定位任务上 , HTS-AT无需额外标注数据 , 即达到有监督定位模型的性能水平 。
在音乐识别场景中 , 声音事件检测模型会挑选包含音乐的片段送入音乐检索系统 , 以此来提高整个系统的效率与准确性 。
2、S3T:针对音乐分类基于SwinTransformer的自监督预训练
这篇文章提出了一种创新的、基于层级式Transformer的自监督音乐预训练算法S3T 。
- 微信音乐自动转视频引吐槽
- 骁龙8+:平衡了性、音乐播放后,这增加是今年最强
- 网易云音乐ios版更新:歌词窗口不透明
- 微信状态听歌怎么添加歌曲 网易云音乐怎么分享到微信状态上
- 微信状态现已支持网易云音乐一键分享功能
- 网易云音乐净收入同比增38.6%,在线音乐服务付费率超20%
- 《英雄联盟》官方公布“虚空女皇”卑尔维斯主题音乐视频
- 字节跳动游戏发行业务线裁员80%官方回应
- 字节跳动独立电商appfanno即将关停
- 音乐产业的时代已经结束了