字节跳动音乐检索系统bytecover2入选

文章图片
文章图片
编辑|ZeR0
智东西6月1日报道 , 近期 , 字节跳动火山语音团队的最新音乐检索系统ByteCover2入选了国际语音技术领域顶会ICASSP2022 。
该系统主要面向音乐信息检索(MIR)领域的重要任务之一——翻唱识别(CSI) , 通过表征学习方法让其具备提取音乐核心特征的能力 , 并且该特征能够对种类繁多的音乐重演绎具有良好的鲁棒性 , 检索速度提高8倍 。
经Da-Tacos数据集上的评估 , 其准确率远超其他方案的SoTA性能 。
除了ByteCover2 , 字节跳动火山语音团队还有多篇论文被ICASSP2022收录 , 内容涵盖智能音乐、音频合成、音频理解、超脑等多个方向 。
一、翻唱识别:设计隐式嵌入降维方法
翻唱识别往往需要对音乐中的一些常见变化具有鲁棒性 , 从而保证系统专注于对音乐旋律走向的建模 。在设计翻唱识别系统时 , 音乐调式偏移、音乐结构变化、音乐节奏变化这三种音乐变化通常会被重点考虑 。
此外 , 抖音平台上每日新增千万量级的用户投稿 , 如何快速应对巨量查询需求 , 提高识别系统的整体吞吐量并同时确保识别准确性 , 也是亟待解决的问题 。
在内部开发返厂识别时 , 字节跳动还面临另一挑战 , 即在设计特征时 , 如何在保障其他性质的前提下尽可能减小特征大小 , 从而减少存储空间 , 降低系统复杂度和成本 。
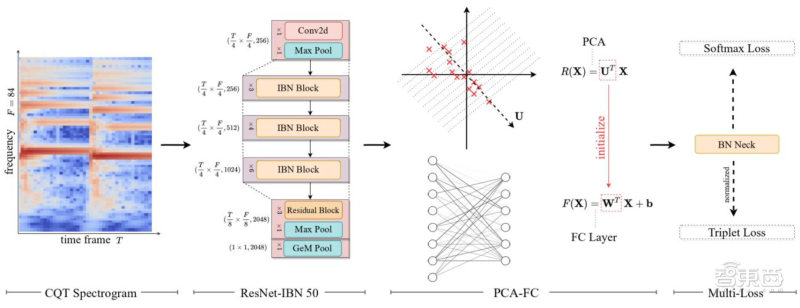
在ByteCover2系统中 , 字节跳动火山语音团队通过多任务学习范式联合ResNet-IBN模型 , 做到从音频输入中提取鲁棒且具备区分性的向量表征 。针对效率优化问题 , 团队还提出了PCA-FC模块 , 实践证明该模块在保证ByteCover2模型性能不变甚至提高的前提下 , 可将向量尺寸压缩至ByteCover1的1/8 。
文章图片
文章图片
▲Bytecover模型结构与训练流程
1、多任务学习提高音乐检索能力
翻唱识别领域通常存在两种训练范式 , 分别是多分类学习和度量学习 。
前者将每个曲目视为一个独立类别 , 在特征层后加上全连接层 , 并通过交叉熵等分类损失对模型进行训练 , 训练完成后去掉全连接层 , 使用特征层的输出作为歌曲的表征;后者直接在特征层之上 , 使用tripletloss等度量学习损失训练网络 。
总体来看 , 两种训练范式各有优劣 , 团队通过实验发现 , 分类损失往往能提高模型对同曲目不同风格版本的检索能力 , 细致设计的度量学习损失则能提高翻唱网络对相似风格不同曲目音乐的区分能力 。
因此ByteCover系列模型对这两种学习范式进行了结合 , 并通过引入BNNeck模块 , 提高了两种损失的兼容性 。
2、ResNet网络与IBN正则化方法(ResNet&Instance-BatchNormalization)
为了简化音乐特征提取的流程 , 加快特征提取速度 , 团队使用CQT频谱图作为模型的输入 , 而不使用在同期其他翻唱识别方法中常用的cremaPCP或其他更为复杂的特征 , 但此设计会天然地在输入特征层面上损害模型对音频频移的鲁棒性 。
因此 , 团队选择卷积神经网络做了音乐表征提取网络 , 希望能利用卷积网络的平移不变性来实现模型对频移的不变性 。
实验证明 , CQT谱+普通ResNet组合已在效率和性能上超过CremaPCP+CNN的设计 。
深入探究 , 团队引入了Instance-BatchNormalization来从网络隐表示的层面进一步学习和风格无关的音乐特征 , 即特征图上不同通道间的均值方差等统计量与输入的风格化特征相关 。IN通过对特征图的通道维度做的归一化处理 , 一定程度上实现了在隐藏表征层面上去除风格化信息 , 从而提高翻唱识别模型对音色变化的鲁棒性 。
- 微信音乐自动转视频引吐槽
- 骁龙8+:平衡了性、音乐播放后,这增加是今年最强
- 网易云音乐ios版更新:歌词窗口不透明
- 微信状态听歌怎么添加歌曲 网易云音乐怎么分享到微信状态上
- 微信状态现已支持网易云音乐一键分享功能
- 网易云音乐净收入同比增38.6%,在线音乐服务付费率超20%
- 《英雄联盟》官方公布“虚空女皇”卑尔维斯主题音乐视频
- 字节跳动游戏发行业务线裁员80%官方回应
- 字节跳动独立电商appfanno即将关停
- 音乐产业的时代已经结束了