NVIDIA实锤:2年前的安培显卡性能依然领先A卡一倍
在显卡市场上 , NVIDIA不论游戏卡还是加速卡都遥遥领先AMD , 哪怕是NVIDIA两年前发布的Ampere架构显卡A100 , 性能也要比AMD去年底发布的InstinctMI250高出一倍多 , 优势明显 。
NVIDIA日前在官方博客中公布了A100加速卡与AMDMI250加速卡的对比 , 测试主要是数据中心中很流行的LAMMPS、NAMD、openMM、GROMACS和AMBER等应用 。
文章图片
文章图片
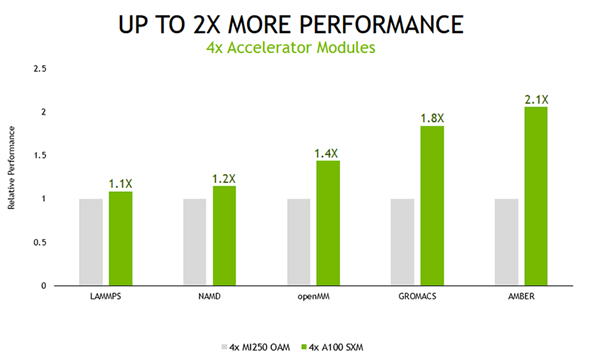
同样是4路GPU配置下 , A100显卡的性能少说高出10% , 多的领先40%以上 , 最高的Amber应用中 , A100的性能优势达到了110% , 高出一倍 。
文章图片
文章图片
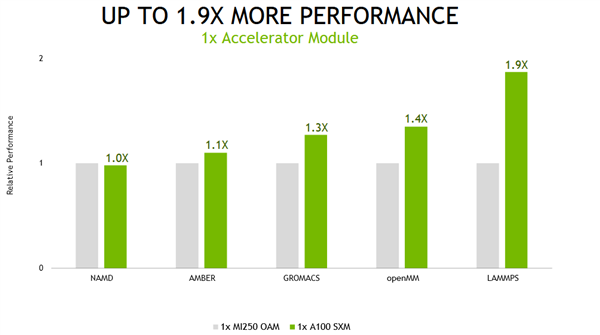
如果是单卡情况下 , A100最多也能领先MI250显卡90%的性能 。
文章图片
文章图片
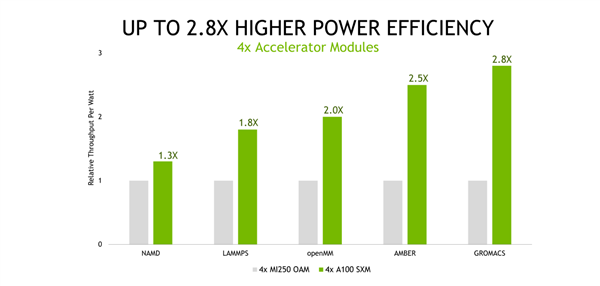
如果是对比能效的话 , NVIDIA这边就更自信了 , A100相比AMD的MI250最多拥有180%的能效优势 , 这对数据中心来说很重要 。
要知道 , A100是NVIDIA2022年5月份发布的加速卡了 , 台积电7nm工艺制造 , 集成多达542亿个晶体管 , 核心面积达826平方毫米 , 内置6912个FP32CUDA核心 , 最高加速频率1.4GHz , 搭配512-bit40GBHBM2显存 , 带宽达1.6TB/s 。
相比上代伏特架构的V100核心 , 它的INT8推理、FP32训练性能提升20倍 , FP64计算性能提升2.5倍 , 是历史上进步最大的一次 。
至于MI250加速卡 , 这是AMD去年11月发布的加速卡 , 升级为新的CDNA2计算架构 , 搭配升级的6nmFinFET工艺 , 580亿个晶体管 , 并使用2.5DEFB桥接技术 , 业内首创多Die整合封装(MCM) , 内部集成了两颗核心 。
InstinctMI250拥有208计算单元、13312流处理器核心 , 搭配8192-bit位宽的128GBHBM2e , 频率1.6GHz , 峰值带宽3276.8GB/s , 并支持全芯片ECC 。
AMD表示InstinctMI200系列性能双精度性能比竞品高出最多4.9倍 , 比上代提升最多4倍 。
巧合的是 , 前几天微软还首发选择了AMD的MI200系列加速卡给云计算提供AI加速 , AMD的那个5倍友商性能很好很强大 , NVIDIA这边马上就发布测试 , 都不用最新的H100加速卡出手 , 2年前的A100加速卡就拿出来对比MI250加速卡了 。

文章图片
文章图片
【NVIDIA实锤:2年前的安培显卡性能依然领先A卡一倍】
文章图片
文章图片
- nvidiartx4090、rtx4070基本敲定8月发布
- 如何让一台 10 年前的 MacBook Air「重获新生」
- 10倍AMD超算性能 NVIDIA开建AI超算:CPU、显卡
- gtx1630将于6月15日开卖
- nvidia400亿美元收购arm,孙正义会否插一脚?
- 3dcenter汇总:amd及nvidia显卡价格变化
- 苹果桌面小组件有哪些功能?
- RTX 30显卡价格暴降!NVIDIA清库存压力大
- 用上NVIDIA T1200专业显卡
- nvidia提交给sec的10-q文件中谈到了一些风险