一组数据中首位为1的出现概率并非1/9,而是1/3,为什么?
【一组数据中首位为1的出现概率并非1/9,而是1/3,为什么?】在工作和生活之中 , 我们总是会接触到各种各样的数据 , 而对于这些数据的真假 , 我们却难以辨别 , 那么有没有什么方法可以让我们迅速对一组数据的真假作出判断呢?有的 , 那就是“本福特定律” 。
当我们拿到一组数据的时候 , 这组数据之中的每一个数字都存在着一个首位 , 举例而言 , 对于1534这个数字来说 , 首位就是1;对于345这个数字来说 , 首位就是3 。首位就是一个数字的第一数位 。现在我们来思考一个问题 , 不同的数字出现在首位的概率是否一样呢?又是多少呢?乍一看这个问题 , 我们很快便能够给出答案 , 那就是任何数字出现在首位的概率都是一样的 , 而且是1/9 。因为能够出现在首位的数字一共有9个 , 分别为1、2、3、4、5、6、7、8、9 , 所以每个数字出现的概率自然应该是1/9 。但事实却并不是这样 。

文章图片
文章图片
早在1881年的时候 , 一个名为纽康的天文学家就发现 , 在一组数据之中 , 不同数字出现在首位的概率是不相同的 , 而在将近60年之后 , 另一个名为“本福特”的物理学家也发现了相同的规律 , 所以这一规律就被称之为“本福特定律” 。
根据本福特定律 , 1作为首位数字出现的概率是最高的 , 大约达到了30% 。真的是这样吗?你可以亲自选取一些数据来进行验证 , 比如某一年世界各国的GDP数据、世界上所有国家的国土面积数据 , 又或者你可以数一数我最近发表的50篇文章的评论数数据 , 你会惊奇地发现首位为1的出现概率真的是接近30%的 。那么这到底是为什么呢?除了1以外 , 2、3、4、5、6在首位出现的概率也可以计算出来吗?当然是可以的 。

文章图片
文章图片
本福特定律是有一个计算公式的 , 即为P(N)=lg((N+1)/N) , 这里的P(N)就代表了数字N在首位出现的概率 。
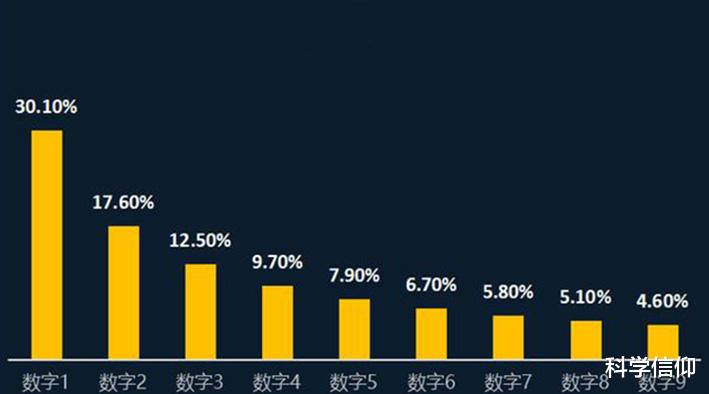
我们首先将1代入这个公式 , 就得到了P(1)=lg2=30.1% , 所以1在首位出现的概率就是30.1% 。再将2代入公式 , 就得到了P(2)=lg3/2=17.6% , 所以2在首位出现的概率就是17.6% 。将3代入公式 , 就得到P(3)=lg4/3=12.5% , 所以3在首位出现的概率就是12.5% 。
后面的数字就不一一计算了 , 直接给出结果:4的概率是9.7%、5的概率是7.9%、6的概率是6.7%、7的概率是5.8%、8的概率是5.1%、9的概率是4.6% 。从最后的结果可知 , 越大的数字出现在首位的概率就越小 。有了这个规律 , 当我们拿到一组数据的时候 , 就可以根据这组数据首位数字的分布规律来对这组数据的真假有一个基本的判断 。
文章图片
文章图片
比如某个投资顾问在向你极力推荐他们的投资产品 , 并拿出了过往10年的月度收益数据时 , 你就可以通过本福特定律来对这组数据的真假有一个初步的判断 , 如果数据明显违背本福特定律 , 那么你有必要通过其它的方式来对这个数据做进一步的核实 。
本福特定律可以应用于任何地方吗?当然不 。本福特定律的应用要满足两个基本条件 , 第一必须是非人为规律的数据 , 比如一个班级的期末考试成绩数据就不行 , 因为分数是人为规定的 , 我们人为地将100分设定为满分 , 自然就不能满足本福特定律 , 否则如果一个班中30%的人都考了10多分 , 可就麻烦了 。第二是数据的跨度必须要大 。比如我文章的评论数 , 很多文章只有2、3个评论 , 也有些文章有三五十个评论 , 还有一些有数百评论 , 数据跨度非常大 , 这就可以应用本福特定律 。如果是一个学校各个班级的人数数据就不行 , 因为跨度太小 , 每个班都是四五十人 , 当然不行了 。
- 郎酒将拓宽红花郎品牌战略阵地 打造红花郎“中国节”IP
- 长安福特蒙迪欧在中国市场的“全球化”
- canalys公布2021年全球个人电脑市场数据
- safari浏览器中的indexeddb漏洞
- 2021年度中国互联网辟谣优秀作品即将发布
- 盲盒梦乐园|盲盒梦乐园怎么抽中隐藏款(盲盒梦乐园隐藏款获取方法)
- 七款新品集中亮相,数说故事超前布局「数据驱动+AI 赋能」应用闭环
- 投票啦!第六届中国文旅IP大会“IP有光”评选全面启动
- 复旦研发智能冰上运动训练分析系统,助中国选手化身“冰雪精灵”
- 一纵一横,搭建完整数据分析体系