继LSTM之父用世界模型来模拟2D赛车后,谷歌又推出全新世界模型助力导航:360度无死角,就问你怕了没?( 三 )
为了将指导图像转换为合理、真实的图像输出 , Pathdreamer 分为两个阶段运行:第一阶段 , 用结构生成器生成分割和深度图像;第二阶段 , 用图像生成器将分割与深度图像渲染为 RGB 输出 。
从概念上讲 , 就是第一阶段提供了关于场景的合理高级语义表示 , 第二阶段再将其渲染为逼真的彩色图像 。这两个阶段都用到了卷积神经网络(CNN):

文章图片
文章图片
在具有高度不确定性的区域 , 比如拐角或视线以外的房间 , 可能会出现许多不同的场景 。而Pathdreamer能够生成满足区域高度不确定的多样化结果 。
有感于受到纽约大学Rob Fergus与Emily Denton提出的随机视频生成思想 , Pathdreamer的结构生成器以噪音变量为条件 , 该变量表示指导图像中没有捕获的下一个导航位置的随机信息 。通过对多个噪音变量进行采样 , Pathdreamer可以合成多个不同场景 , 允许智能体在一条给定的导航路线中对多个合理的结果进行采样 。
这些不同的输出不仅反映在第一阶段的输出(语义分割和深度图像)中 , 还反映在生成的 RGB 图像中 。
如下图所示 , 最左侧的一列指导图像表示智能体先前看到的像素 。其中 , 黑色像素表示智能体原先看不见的区域 , 对此 , Pathdreamer 通过对多个随机噪声向量进行采样 , 生成了不同的图像输出 。在实践中 , 当智能体在一个环境中定位导航时 , 它可以通过新的观察结果来生成输出图像 。

文章图片
文章图片
Pathdreamer 基于来自 Matterport3D 的图像和 3D 环境重建进行训练 , 并且能够合成逼真的图像与连续的视频序列 。由于输出图像具有高分辨率和 360o 无死角的特征 , 现有的导航机器人可以轻松地将图像转换 , 以适应机器人配有的相机视野 。
4、将Pathdreamer应用于视觉导航任务
他们将 Pathdreamer 应用于视觉与语言导航 (VLN) 任务 , 其中 , 机器人必须遵循自然语言的指令定位到真实 3D 环境中的某一个位置 。他们使用 Room-to-Room(R2R)数据集进行了一项实验 , 让指令机器人在模拟多条可能的行走轨迹前进行规划 , 并根据导航指令对每一条轨迹进行排名 , 然后选择排名第一的轨迹进行导航 。
实验考虑了三种设置:
1)地面实况(ground truth)设置:机器人通过与真实的环境互动(比如移动)来进行规划;
2)基线(Baseline)设置:机器人提前规划 , 无需与导航图交互、对建筑内的导航路线进行编码 , 但没有提供任何视觉观察;
3)Pathdreamer 设置:机器人提前规划 , 无需与导航图交互 , 且还能接收到Pathdreamer所生成的对应视觉观察 。
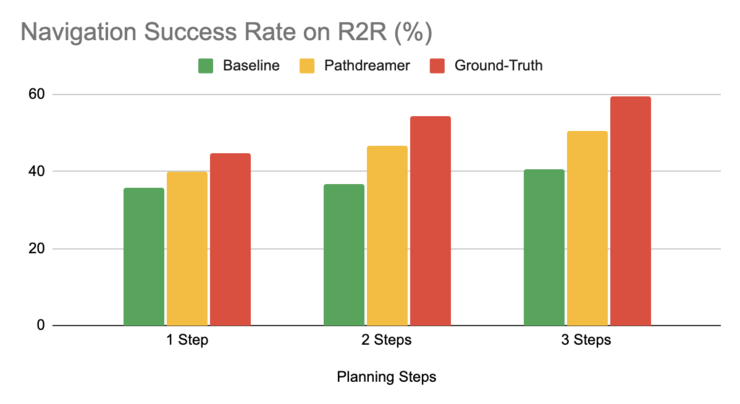
在Pathdreamer设置中 , 机器人提前三步(大约6米)规划 , 导航成功率高达 50.4% , 而基线设置的成功率只有 40.6% 。这表明 , Pathdreamer对现实室内环境中的有用、且可以访问的视觉、空间与语义知识进行了编码 。
而在地面实况的设置中 , 机器人通过移动进行规划 , 导航成功率达到了 59% 。不过 , 地面实况设置要求机器人花费大量的时间与资源进行多轨迹探索 , 在现实世界中的代价可能十分高昂 。
文章图片
文章图片
图注:VLN机器人在三种设置(地面实况、基线与Pathdreamer)中的表现
实验结果表明 , 类似 Pathdreamer 的世界模型在处理复杂的导航任务中具有出色表现 。
- 战神4PC版|《战神4》PC版PS4存档继承法(可用PS4存档开启“新游戏+”二周目)
- 鬼泣巅峰之战强大自身继续调查什么意思(鬼泣巅峰之战第十三章通关提示内容解析)
- 江湖悠悠武器强化效果能不能继承(江湖悠悠武器强化效果继承机制分享)
- 王者荣耀新赛季战令能继承多少级(王者荣耀新赛季战令等级继承详情一览)
- 摩尔庄园手游继承页游的物品吗(摩尔庄园手游与页游互通问题说明)
- 战神遗迹装备强化效果能不能继承(战神遗迹装备强化效果继承机制解析)
- 微信语音支持暂停和继续播放,再也不怕老板、客户60秒长语音从头听了
- RTX 3060 Ti或将出新版:GA103核心
- ios版微信更新,语音暂停后继续播放功能登上热搜
- 肯德基盲盒被批诱导不理性消费,客服:仍在继续,售罄不再补