当世界模型被用于sim2real:机器人通过视觉想象和交互尝试来学习

文章图片
文章图片
具备学习技能的机器人必须能在不同的环境中执行不同的任务 。当机器人遇到新的环境或物体时 , 它可能需要微调一些先前的技能以适应这种变化 。但至关重要的是 , 以前学习的行为和模型应该仍适用于这种新学习 。
编译 | 杏花
编辑 | 青暮
人类是如何掌握这么多技能的呢?好吧 , 最初我们并非如此 , 但从婴儿时期开始 , 我们通过自监督发觉并练习越来越复杂的技能 。但这种自监督并不是随机的——儿童发展文献表明 , 婴儿利用他们先前的经验 , 通过互动和感官反馈 , 对移动性、吸吮性、抓握性和消化性等可供性(affordance , 也译作功能可供性、承担特质、直观功能、预设用途、可操作暗示、示能性等 , 指事物能够提示其可以帮助人们做什么的一种属性或特征)进行定向探索 。这种类型的定向探索允许婴儿在既定环境中学习可以做什么以及如何做 。那么 , 在机器人学习系统中 , 我们是否也可以实例一个类似于可供性定向探索的策略?

文章图片
文章图片
如下图所示 。在左侧 , 我们先收集了由机器人完成各种任务的视频 , 比如打开和关闭抽屉、抓取和移动物体 。在右侧 , 我们放置了一个机器人从未见过的盖子 。机器人被给予一小段时间来熟悉这个新物体 , 之后它将获得一个目标图像 , 并负责使场景匹配这个图像 。机器人如何在没有任何外部监督的情况下迅速学会操控环境并抓住盖子?

文章图片
文章图片
为此 , 我们面临几项挑战 。当机器人被置于一个新环境时 , 它必须能够利用其先前的知识来思考环境可能提供的潜在有用行为 。然后 , 机器人必须能够实际地练习这些行为 。为了在新的环境中改进自己 , 机器人必须能够在没有外部奖励的情况下以某种方式评估自己的成功 。
如果我们能可靠地战胜这些挑战 , 就能为一个强有力的循环打开大门 。在这个循环中 , 我们的智能体使用先前的经验来收集高质量的交互数据 , 然后进一步增长它们以往的经验 , 不断提高它们的潜在效用!
1
VAL:视觉运动可供性学习
我们的方法 , 视觉运动可供性学习(Visuomotor Affordance Learning , 简称VAL) , 解决了这些挑战 。在VAL中 , 我们首先假设可以获得机器人在各种环境中展示可供性的先验数据集 。至此 , VAL进入了一个离线阶段 , 该阶段使用这些信息学习 1)想象新环境中有用的可供性生成模型 , 2) 用于有效探索这些可供性的强大离线策略 , 以及 3) 改进该策略的自我评估度量 。最后 , VAL已准备好进入在线阶段 。智能体被放置在一个新的环境中 , 现在可以使用这些学到的功能来进行自监督的微调 。整个框架如下图所示 。随后 , 我们将深入探讨离线和在线阶段的技术细节 。
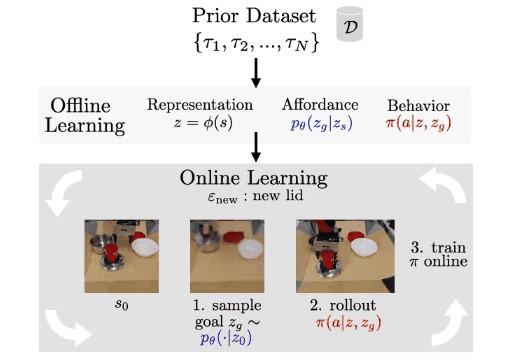
文章图片
文章图片
2
VAL:离线阶段
给定一个展示各种环境可供性的先验数据集 , VAL在三个离线步骤中消化这些信息:用于处理高维真实世界数据的表示学习 , 在未知环境中实现自监督练习的可供性学习 , 用于获得高性能的初始策略以加快在线学习效率的行为学习 。
- AI技术创新、模型创新、业务创新 全新服务模式助力金融机构数字化转型
- 我的世界大闹天宫龙宫怎么玩(我的世界大闹天宫龙宫打法技巧一览)
- “会省钱”成了当代青年的阶层分界线
- 微博电竞|当电竞携手公益事业(看微博电竞全明星公益赛跨界破圈的秘诀)
- 我的世界手游龙蛋怎么拿(我的世界手游龙蛋获得方式分享)
- 我的世界白虎雷泽皮肤外观是怎样的(我的世界白虎雷泽皮肤样式分享)
- 我的世界黑豹影流皮肤什么样(我的世界黑豹影流皮肤外观一览)
- 阴阳师世界密语|阴阳师世界密语汇总(SP山兔活动兔兔忍法帖世界密语一览)
- 【星辰大海】“经略海洋”中集担当:“担”起大国重器,“当”在自主创新
- 阴阳师世界密语(阴阳师兔兔忍法帖世界密语是什么)