当世界模型被用于sim2real:机器人通过视觉想象和交互尝试来学习( 二 )
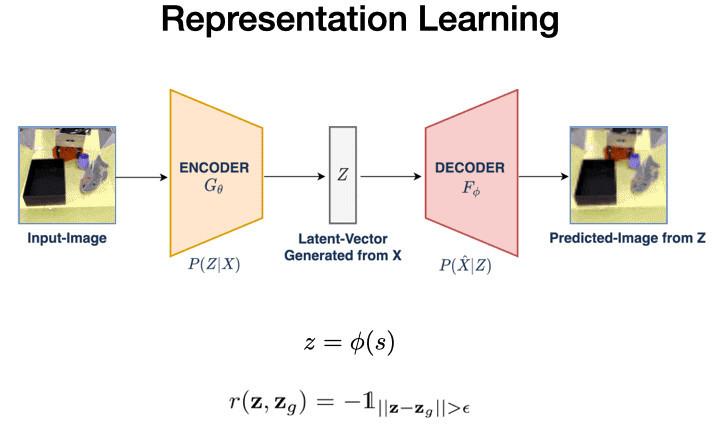
1. 首先 , VAL使用矢量量化变分自动编码器(VQVAE)学习该数据的低维表示 。这个过程将我们的48x48x3图像压缩到144维的潜在空间 。
文章图片
文章图片
在这个潜在空间的距离是有意义的 , 为我们自我评价成功的关键机制铺平了道路 。给定当前图像s和目标图像g , 我们将它们编码进潜在空间 , 并设定它们可以获得奖励的距离阈值 。
随后 , 我们还将使用这个表示作为我们潜在空间的策略和Q函数 。
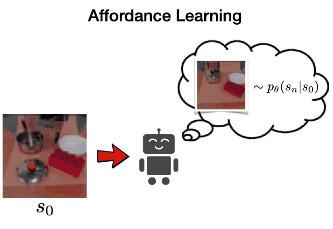
2.接下来 , VAL 通过在潜在空间中训练 PixelCNN 来学习可供性模型 , 以学习以环境图像为条件的可达状态分布 。这是通过最大化数据的似然 p(sn|s0) 来完成的 。我们使用这种可供性模型进行定向探索和重新标记目标 。
文章图片
文章图片
可供性模型如右图所示 。在该图的左下方 , 我们看到条件图像包含一个罐子 , 右上方解码的潜在目标显示了不同位置的盖子 。这些连贯的目标将允许机器人进行连贯的探索 。
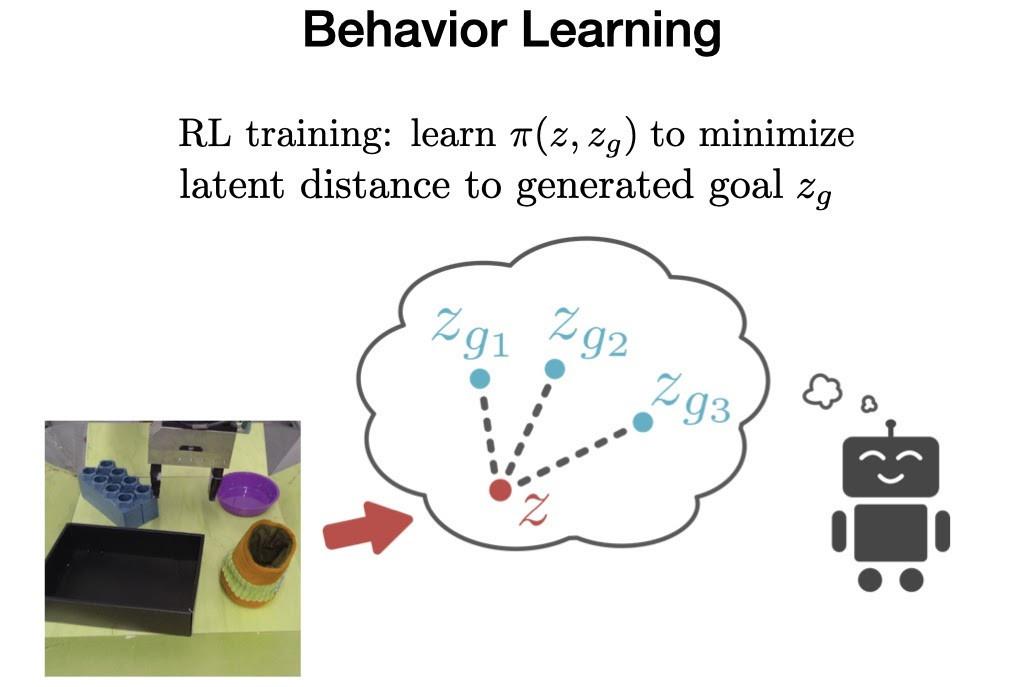
3. 最后在离线阶段 , VAL必须从离线数据中学习行为 , 然后可以通过额外的在线交互式数据收集进行改进 。
文章图片
文章图片
为了实现这一点 , 我们使用加权强化学习算法(Advantage Weighted Actor Critic)在先验数据集上训练目标条件策略 , 这是一种专为离线训练和在线微调而设计的算法 。
3
VAL:在线阶段
现在 , 当VAL被放置在一个未见过的环境中时 , 它使用其先前的知识来想象有用可供性的视觉表示 , 通过尝试实现这些可供性来收集有用的交互数据 , 使用其自我评估指标更新其参数 , 并一直重复整个过程 。
文章图片
文章图片
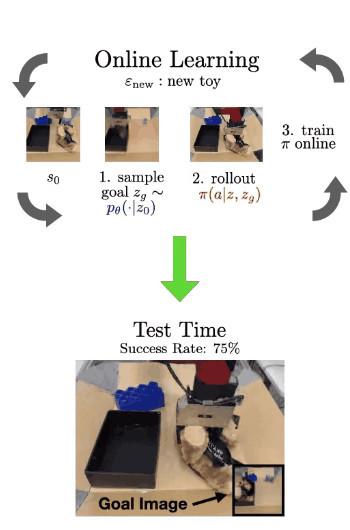
在这个真实的例子中 , 在左侧我们看到了环境的初始状态 , 它提供了打开抽屉和其他任务的功能 。
在步骤1中 , 可供性模型对潜在目标进行采样 。通过解码目标(使用 VQVAE 解码器 , 在RL期间从未实际使用过 , 因为我们完全在潜在空间中操作) , 我们可以看到可供性是打开抽屉 。
在步骤2中 , 我们使用具有采样目标的训练策略 。我们看到它成功打开了抽屉 , 实际上它拉太大力了 , 直接把抽屉拉了出来 。但这为RL算法进一步微调和完善其策略提供了极其有用的交互 。
在线微调完成后 , 我们现在可以评估机器人在每个环境中实现相应的未见过的目标图像的能力 。
4
真实环境评估
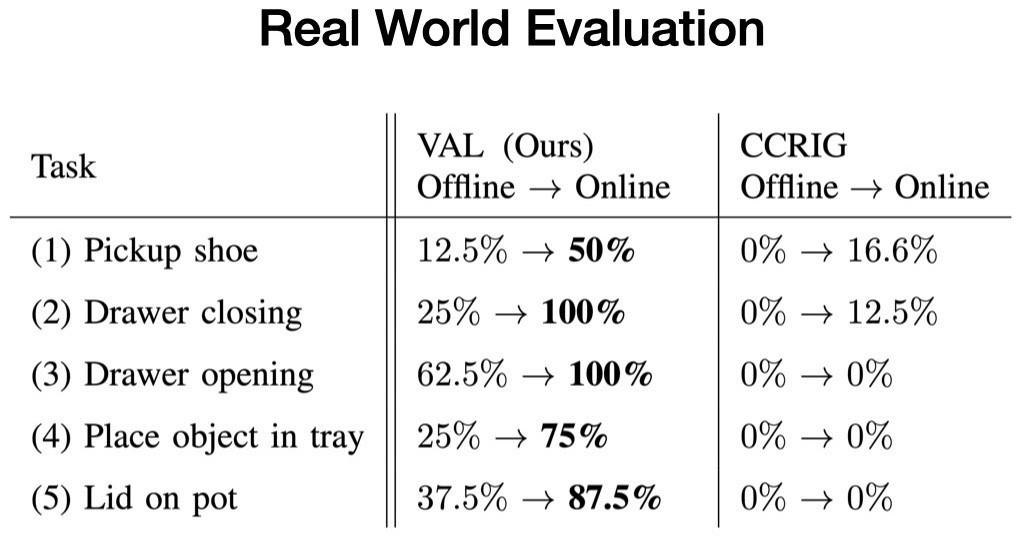
我们在五个真实的测试环境中评估我们的方法 , 并评估VAL在无监督微调之前和五分钟之后完成环境提供的特定任务的能力 。
每个测试环境至少包含一个未见过的交互对象和两个随机抽样的干扰对象 。例如 , 当训练数据中有打开和关闭抽屉时 , 新的抽屉有没见过的把手 。
文章图片
文章图片
每个测试 , 我们都从离线训练策略开始 , 它每次完成任务的方式都不一致 。然后 , 我们使用我们的可供性模型收集更多经验来采样目标 。最后 , 我们评估经过微调的策略 , 它能始终一致地完成任务 。

- AI技术创新、模型创新、业务创新 全新服务模式助力金融机构数字化转型
- 我的世界大闹天宫龙宫怎么玩(我的世界大闹天宫龙宫打法技巧一览)
- “会省钱”成了当代青年的阶层分界线
- 微博电竞|当电竞携手公益事业(看微博电竞全明星公益赛跨界破圈的秘诀)
- 我的世界手游龙蛋怎么拿(我的世界手游龙蛋获得方式分享)
- 我的世界白虎雷泽皮肤外观是怎样的(我的世界白虎雷泽皮肤样式分享)
- 我的世界黑豹影流皮肤什么样(我的世界黑豹影流皮肤外观一览)
- 阴阳师世界密语|阴阳师世界密语汇总(SP山兔活动兔兔忍法帖世界密语一览)
- 【星辰大海】“经略海洋”中集担当:“担”起大国重器,“当”在自主创新
- 阴阳师世界密语(阴阳师兔兔忍法帖世界密语是什么)