只用一张上图+相机感知偏差,ai就能脑补
黑龙江龙网_原标题:只用一张图+相机走位 , AI就能脑补周围环境 , 来自华人团队|CVPR2022
站在门口看一眼 , AI就能脑补出房间里面长什么样:

文章图片
文章图片
是不是有线上VR看房那味儿了?
不只是室内效果 , 来个远景长镜头航拍也是soeasy:

文章图片
文章图片
而且渲染出的图像通通都是高保真效果 , 仿佛是用真相机拍出来的一样 。
最近一段时间 , 用2D图片合成3D场景的研究火了一波又一波 。
但是过去的许多研究 , 合成场景往往都局限在一个范围比较小的空间里 。
比如此前大火的NeRF , 效果就是围绕画面主体展开 。
这一次的新进展 , 则是将视角进一步延伸 , 更侧重让AI预测出远距离的画面 。
比如给出一个房间门口 , 它就能合成穿过门、走过走廊后的场景了 。
目前 , 该研究的相关论文已被CVPR2022接收 。
输入单张画面和相机轨迹
让AI根据一个画面 , 就推测出后面的内容 , 这个感觉是不是和让AI写文章有点类似?
实际上 , 研究人员这次用到的正是NLP领域常用的Transformer 。
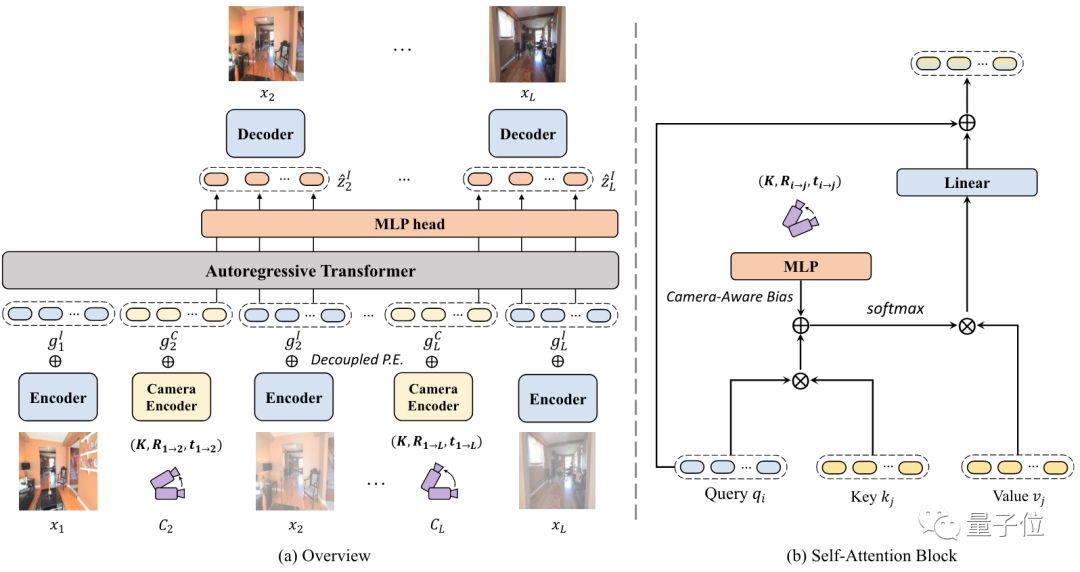
他们利用自回归Transformer的方法 , 通过输入单个场景图像和摄像机运动轨迹 , 让生成的每帧画面与运动轨迹位置一一对应 , 从而合成出一个远距离的长镜头效果 。
文章图片
文章图片
整个过程可以分为两个阶段 。
第一阶段先预训练了一个VQ-GAN , 可以把输入图像映射到token上 。
VQ-GAN是一个基于Transformer的图像生成模型 , 其最大特点就是生成的图像非常高清 。
在这部分 , 编码器会将图像编码为离散表示 , 解码器将表示映射为高保真输出 。
第二阶段 , 在将图像处理成token后 , 研究人员用了类似GPT的架构来做自回归 。
具体训练过程中 , 要将输入图像和起始相机轨迹位置编码为特定模态的token , 同时添加一个解耦的位置输入P.E. 。
然后 , token被喂给自回归Transformer来预测图像 。
模型从输入的单个图像开始推理 , 并通过预测前后帧来不断增加输入 。
研究人员发现 , 并非每个轨迹时刻生成的帧都同样重要 。因此 , 他们还利用了一个局部性约束来引导模型更专注于关键帧的输出 。
【只用一张上图+相机感知偏差,ai就能脑补】这个局部性约束是通过摄像机轨迹来引入的 。
基于两帧画面所对应的摄像机轨迹位置 , 研究人员可以定位重叠帧 , 并能确定下一帧在哪 。
为了结合以上内容 , 他们利用MLP计算了一个“相机感知偏差” 。
这种方法会使得在优化时更加容易 , 而且对保证生成画面的一致性上 , 起到了至关重要的作用 。
实验结果
本项研究在RealEstate10K、Matterport3D数据集上进行实验 。
结果显示 , 相较于不规定相机轨迹的模型 , 该方法生成图像的质量更好 。
与离散相机轨迹的方法相比 , 该方法的效果也明显更好 。
作者还对模型的注意力情况进行了可视化分析 。
结果显示 , 运动轨迹位置附近贡献的注意力更多 。

文章图片
文章图片
在消融实验上 , 结果显示该方法在Matterport3D数据集上 , 相机感知偏差和解耦位置的嵌入 , 都对提高图像质量和帧与帧之间的一致性有所帮助 。
- 15楼财经|今麦郎澄清“日资”身份重申是民营企业 一张图片却引网友争议
- 詹姆斯·韦伯望远镜终于传回第一张清晰照片
- 好奇号漫游车在火星上拍到一张奇特的照片
- 数字孪生用于环境治理,腾讯助力北京打造生态信息“一张图”
- nasa公布韦伯望远镜利用近红外相机拍摄的第一张照片
- 林草科技|林业和草原科技创新“一张图”专家研讨会在京召开
- 特斯拉又收到一张来自美国证券交易委员会(sec)传票
- 4毫米厚一张网能承受20吨拉力?云顶场馆有项“黑科技”
- 2021年,玉林做了啥?2022年,我们要做啥?一张图告诉你!
- 毕节年货节,来了