colossal-ai打破“内存墙限制”
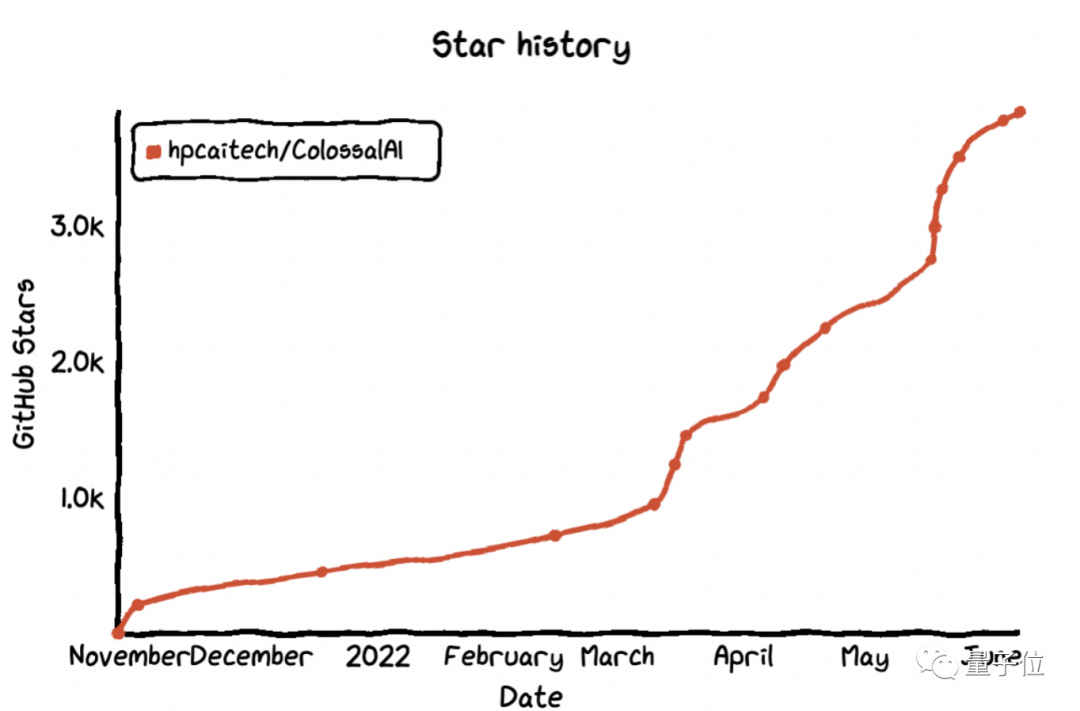
不得不说 , Colossal-AI训练系统这个开源项目的涨星速度是真快 。
在“没十几块显卡玩不起大模型”的当下 , 它硬是只用一张消费级显卡 , 成功单挑了180亿参数的大模型 。
难怪每逢新版本发布前后 , 都会连续好几天霸榜GitHub热门第一 。
文章图片
文章图片
△使用github-star-history制图
之前我们也介绍过 , Colossal-AI的一个重点就是打破了内存墙限制 , 如训练GPT-2与英伟达自己的Megatron-LM , 相比GPU显存最高能节省91.2% 。
随着AI模型参数量的不断增长 , 内存不够的问题逐渐凸显 , 一句CUDAoutofmemory让不少从业者头疼 。
甚至伯克利AI实验室学者AmirGholami一年前曾发出预言 , 未来内存墙将是比算力更大的瓶颈:
内存容量上 , GPU单卡显存容量每两年才翻倍 , 需要支撑的模型参数却接近指数级增长 。
传输带宽上 , 过去20年才增长30倍 , 更是远远比不上算力20年增长9万倍的速度 。
因此 , 从芯片内部到芯片之间 , 甚至是AI加速器之间的数据通信 , 都阻碍着AI进一步发展和落地 。
为了搞定这个问题 , 全行业都在从不同角度想办法 。
为了打破内存墙 , 业界做出哪些努力?
首先 , 从模型算法本身入手减少内存使用量 。
比如斯坦福&纽约州立大学布法罗分校团队提出的FlashAttention , 给注意力算法加上IO感知能力 , 速度比PyTorch标准Attention快了2-4倍 , 所需内存也仅是其5%-20% 。

文章图片
文章图片
△arxiv.org/abs/2205.14135
又比如 , 东京大学&商汤&悉尼大学团队提出将分层ViT与掩码图像建模整合在一起的新方法 。内存使用量比之前方法减少了70% 。

文章图片
文章图片
△arxiv.org/abs/2205.13515
同类研究其实层出不穷 , 就先列举最近发表的这两个成果 。
这些单独的方法虽然有效但应用面较窄 , 需要根据不同算法和任务做针对性的设计 , 不太能泛化 。
接下来 , 被寄予厚望能解决内存墙问题的还有存算一体芯片 。
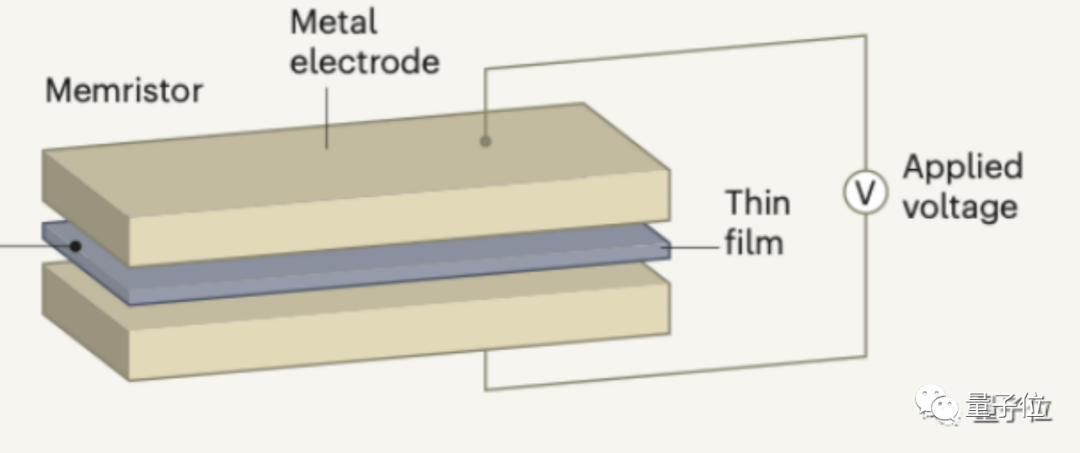
这种新型芯片架构在存储单元中嵌入计算能力 , 以此消除数据搬运的时延和功耗 , 来突破冯诺依曼瓶颈 。
存算一体芯片以忆阻器技术为代表 , 这种电路元件阻值会随着通过的电流改变 , 如果电流停止 , 电阻会停留在当前值 , 相当于“记住”了电流量 。
如果把高阻值定义为1 , 低阻值定义为0 , 忆阻器就可以同时实现二进制的计算和存储 。
文章图片
文章图片
△来自doi:10.1038/s41586-021-03748-0
不过存算一体芯片行业还在起步阶段 , 需要材料学的进步来推动 。一方面 , 能做到量产的就不多 , 另一方面也缺少对应的编译器等软件基础设施支持 , 所以离真正大规模应用还有一段距离 。
当下 , 基于现有软硬件框架做优化就成了比较务实的选项 。
如前面提到的Colossal-AI , 用多维并行的方式减少多GPU并行时相互之间的通信次数 , 又通过向CPU“借内存”的方法让GPU单卡也能训练大模型 。
具体来说 , 是根据动态查询到的内存使用情况 , 不断动态转换张量状态、调整张量位置 , 高效利用GPU+CPU异构内存 。
这样一来 , 当AI训练出现算力足够但内存不够的情况时 , 只需加钱添购DRAM内存即可 , 这听起来可比买GPU划算多了 。
- 线上线下花式促销!太原“6·18”年中大促火热进行
- qqv8.8.95版本推出“智能视频字幕”功能
- 第四届数字中国技术年会“场景金融·新引擎”主题论坛在西安召开
- 国内首次!“襄阳造”千吨级架桥机成功自转调头
- b站“轻视频”app停运公告:6月30日停运下线
- 618购物节陕西老字号受青睐 多个品牌火热“出圈”
- 极“智”技艺,造就极“质”底气
- 富豪纷纷入局“重返年轻”技术:贝索斯30亿美元搭上末班车
- 第七届“创客中国”卫星产业链赛道赛正式拉开帷幕
- 推动数字经济高质量发展,寻找“数字中国”的“上海范本”