数据编排支持人工智能(AI)的下一步发展( 二 )
数据编排的应用场景
在数据中心、边缘计算和嵌入式系统部署等应用场景中 , 有许多不同类型的数据编排架构 。例如 , 在数据中心应用环境中 , 多个加速器可以部署在单个模型上 , 它们的数据吞吐量由一个或多个数据编排引擎管理 。
推理系统需要数据编排来确保每个工作引擎的最大效用 , 以避免瓶颈 , 并确保尽可能快地处理输入的数据样本 。分布式训练增加了对神经元权重快速更新的要求 , 这些更新必须尽快分配给处理相关模型部件的其他工作引擎 , 以避免停滞 。
FPGA中的数据编排逻辑支持处理广泛的权重分配和同步协议 , 以支持高效的运行 , 同时减轻加速器本身的数据组织负担 。下图展示了一种可能的实现方法 , 使用一个FPGA器件管理同一块电路板上的多个人工智能引擎 。使用一种合适的低噪声通信协议 , 单个机器学习专用集成电路(ASIC)不需要存储控制器 。相反 , 数据编排引擎在本地存储器中组织所有的权重和数据元素 , 并简单地将它们以合适的顺序传输到它所管理的每个ASIC 。其结果是通过减少重复的存储和接口逻辑 , 以更低的总体成本获得高性能 。
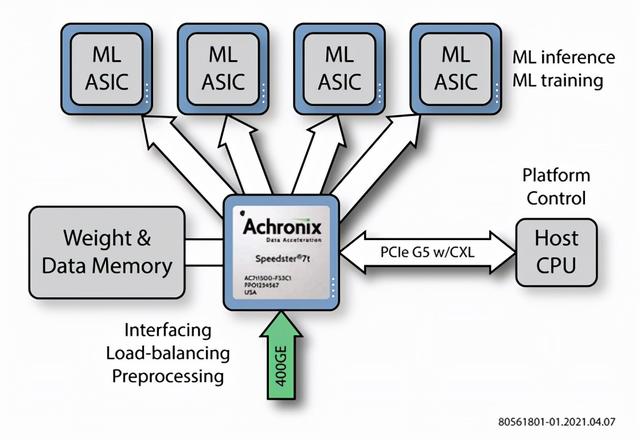
文章图片
文章图片
图1:数据编排可以为并行化的人工智能实现应用快速地提供负载平衡和其他数据转发功能
利用数据编排 , 硬件可以在不增加成本的情况下进一步提高性能 。一种选择是利用网络或系统总线数据的压缩 , 避免使用更昂贵的互连 。FPGA的逻辑层面可编程性支持通过网络接口对数据进行压缩和解压缩 。数据编排硬件还支持使用前向纠错协议来确保以全流水线速度传输有效数据 。在大多数设计中 , 损坏事件通常很少发生 , 但是如果没有外部的纠错支持 , 那么对于高度流水线化的加速器设计来说 , 恢复成本将会很高 。
图2展示了数据编排引擎可以通过多种方式优化数据流和给机器学习引擎提供的呈现结果 。
例如 , 单个数据元素的格式和结构为利用数据编排的优势提供了一个重要的机会 , 因为源数据通常必须以一种适合深度神经网络(DNN)进行特征提取的格式来表示 。
在图像识别和分类应用中 , 像素数据通常被通道化 , 以便在通过提取形状和其他高级信息的池化层进行聚合结果之前 , 可以单独处理每个颜色平面 。通道化有助于识别边缘和其他特征 , 这些特征可能不易于用组合的RGB表示法识别 。在语音和语言处理中会执行更广泛的转换 。数据通常被映射成一种更容易被DNN处理的形式 。由于不是直接处理ASCII或Unicode字符 , 而是将模型中要处理的词和子词转换为向量和one-hot表示 。类似地 , 语音数据可能不会以原始时域样本的形式呈现 , 而是转换为联合时频表示 , 从而使重要特征更容易被早期DNN层识别 。
尽管数据转换可以通过人工智能加速器中的算术内核来执行 , 但它可能不太适合张量引擎 。重新格式化的性质使其适合由基于FPGA的模块进行处理 。FPGA能够有效地以线速度进行转换 , 而不会出现在通用处理器上运行软件时所产生的延迟 。
在涉及传感器的实时和嵌入式应用中 , 预处理数据可以带来更多的好处 。例如 , 虽然可以通过训练DNN以消除噪声和环境条件变化的影响 , 但使用前端信号处理对数据进行去噪或归一化处理 , 可提高其可靠性 。在汽车先进驾驶辅助系统(ADAS)实现中 , 摄像头系统必须处理照明条件的变化 。通常 , 通过使用亮度和对比度调整 , 可以利用传感器中高水平的动态范围 。FPGA可以执行必要的操作 , 为DNN提供变化较少的像素流 。
- canalys公布2021年全球个人电脑市场数据
- 小米11tpro印度首销:支持120w超级闪充
- 七款新品集中亮相,数说故事超前布局「数据驱动+AI 赋能」应用闭环
- 一纵一横,搭建完整数据分析体系
- 精灵魔塔数据互不互通(精灵魔塔ios安卓互通问题说明)
- 小米机器狗“铁蛋”升级,支持app快连
- 复苏的魔女官服和渠道服可以互通吗(复苏的魔女游戏数据互通问题说明)
- 上海空调清洗消毒大数据平台全新升级
- 杭州亚运会官方智能物联及大数据服务赞助商签约发布
- 摸金校尉之九幽将军安卓和苹果互通吗(摸金校尉之九幽将军安卓与ios数据互通问题讲解)