数据编排支持人工智能(AI)的下一步发展( 四 )
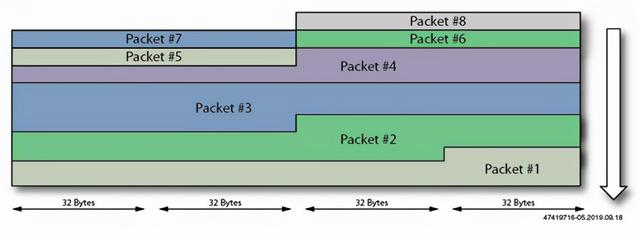
二维片上网络提供的一项重要功能是分组模式(Packet Mode) , 该模式旨在更容易地将到达高带宽端口(如以太网)的数据重新排列为多个数据流 。分组模式可以分离到达速率为200Gb/s或400Gb/s以太网端口的数据包 , 并将它们传输到不同的软核 。这种数据包分离如下图所示 , 连续的数据包被分布到FPGA的不同部分 。因此 , 分组模式可以轻松创建负载平衡架构 , 而使用传统FPGA是难以实现这样的功能 。
文章图片
文章图片
文章图片
文章图片
图3:片上网络的分组模式支持将网络有效负载自动分配到架构的不同部分
另一个好处是 , 二维片上网络更容易支持部分重新配置:二维阵列中的每个逻辑模块都能作为一个可隔离的资源 , 可以在不影响任何其他逻辑模块的情况下完成交换新功能 。由二维片上网络和接入点控制器实现的虚拟化和转换逻辑进一步增强了此功能 。
地址转换表的作用类似于微处理器中的存储管理单元 , 以防止任务之间的数据相互干扰 。接入点中的地址转换表意味着每个软核可以访问相同的虚拟地址范围 , 但访问外部物理存储的范围完全不同 。访问保护位提供了进一步的安全性 , 防止内核访问受保护的地址范围 。在一系列基于人工智能的应用中 , 这种级别的保护很可能变得极其重要 。在这些应用中 , 数据编排和其他可编程逻辑功能在集成到最终产品之前由不同的团队实现 。
除了高度灵活的数据路由 , 数据编排还需要去应用快速算术功能来增强核心人工智能加速器 。Speedster7t FPGA部署了一系列机器学习处理器(MLP)模块 。每个MLP都是一个高度可配置的、计算密集型的模块 , 最多可配置32个乘法器 , 提供高达60 TOPS的性能 。MLP支持4到24位的整数格式和各种浮点模式 , 包括直接支持Tensorflow的bfloat16格式和块浮点(BFP)格式 。周围的可编程逻辑架构提供了多种方法来优化数据流 , 以充分利用MLP提供的数据重用和吞吐量机会 。
由于数据编排硬件需要适用于各种应用环境 , 因此对灵活部署有着明确的需求 。数据中心应用可能需要使用一个或多个分立的、大容量器件(例如Speedster7t FPGA器件) , 来为单个电路板上或分布在一个托盘或机架内的多个机器学习引擎路由和预处理数据流 。对于尺寸、功耗和成本是主要限制因素的边缘计算应用来说 , 采用系统级芯片(SoC)解决方案存在明显的争论 。
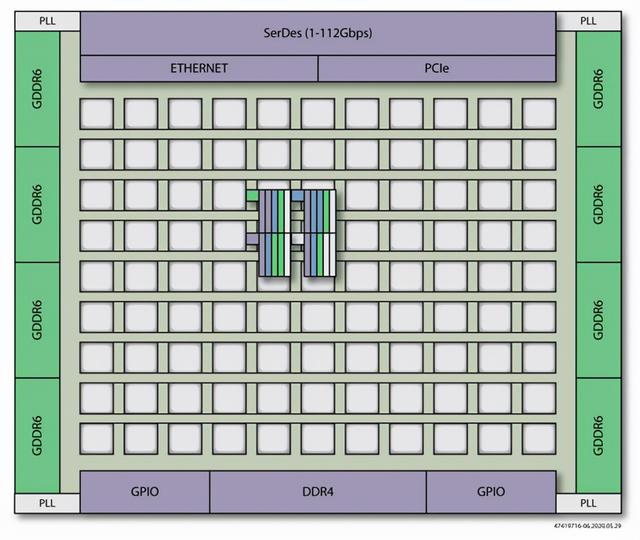
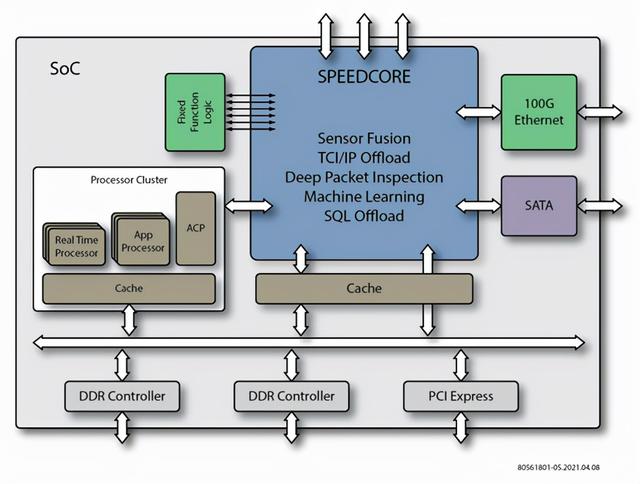
Achronix是唯一一家能够同时提供独立FPGA芯片和嵌入式FPGA(eFPGA)半导体知识产权(IP)技术的公司 , 因此在支持成本降低计划方面具有独特的优势 , 其中可编程逻辑和互连功能可以集成到一个SoC中 , 如下图所示 。Speedcore eFPGA IP使用与Speedster7t FPGA相同的技术 , 支持从Speedster7t FPGA到集成Speedcore模块的ASIC的无缝转换 。当使用Speedcore IP将Speedster7t FPGA转换为ASIC时 , 客户有望降低高达50%的功耗和节省高达90%的单位成本 。
另一种选择是在多芯片模块中使用多芯片合封chiplets 。这在基于FPGA的合封的数据编排模块和机器学习引擎之间提供了高速互连的好处 。Achronix支持所有这些实现选项 。
文章图片
文章图片
图4:嵌入式FPGA技术能够将数据编排集成到加速器芯片中
结论
深度学习的快速发展给大规模实现该技术所需的硬件架构带来了巨大压力 。尽管由于意识到性能是一个绝对要求 , 因此业界高度关注峰值TOPS分数 , 但智能数据编排和管理策略提供了一种用于交付高成本效益和高能效系统的方法 。
- canalys公布2021年全球个人电脑市场数据
- 小米11tpro印度首销:支持120w超级闪充
- 七款新品集中亮相,数说故事超前布局「数据驱动+AI 赋能」应用闭环
- 一纵一横,搭建完整数据分析体系
- 精灵魔塔数据互不互通(精灵魔塔ios安卓互通问题说明)
- 小米机器狗“铁蛋”升级,支持app快连
- 复苏的魔女官服和渠道服可以互通吗(复苏的魔女游戏数据互通问题说明)
- 上海空调清洗消毒大数据平台全新升级
- 杭州亚运会官方智能物联及大数据服务赞助商签约发布
- 摸金校尉之九幽将军安卓和苹果互通吗(摸金校尉之九幽将军安卓与ios数据互通问题讲解)