2022世界人工智能大会|看图更准,能理解视频和做翻译的“书生2.0”来了
本文转自:新民网

文章图片
文章图片
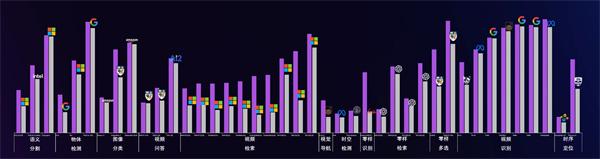
图说:“书生2.0”在40多种图像和视频任务中取得领先性能
2022世界人工智能大会科学前沿全体会议期间 , 上海人工智能实验室发布了更为通用的人工智能模型“书生2.0” 。全新升级后的“书生” , 不但“看图更准” , 还学会了“理解视频”和“做翻译” , 在四十多个视觉任务取得了世界领先性能 。采访人员获悉 , 以中文为核心的大规模百语翻译开源平台也将在年内推出 。
“实验室正在打造以视觉和自然语言为核心的通用模型技术体系 , 包括基础理论方法、数据集、模型集、下游任务和应用生态等 。”上海人工智能实验室领军科学家乔宇表示 , “面向未来 , ‘书生’期望实现以一个模型谱系完成上千种任务 , 体系化解决人工智能发展中的诸多瓶颈问题 。推动人工智能从单任务单模态可用到多任务多模态安全易用 , 从感知智能到认知智能的跃迁 。”
视觉模型更通用、更低碳、更环保
发展更为通用的AI技术是人工智能的科技前沿和核心焦点问题 。去年11月 , 上海人工智能实验室发布“书生” , 一个模型即可全面覆盖分类、目标检测、语义分割、深度估计四大视觉核心任务 。将通用视觉技术体系命名为“书生” , 意在体现其如同书生一般的特质 , 可通过持续学习 , 举一反三 , 逐步实现通用视觉领域的融会贯通 , 最终实现灵活高效的模型部署 。经过近一年的努力 , “书生2.0”全新升级 , 可以更加精准地识别图像 , 在图像标杆任务上性能取得了显著的提升 , 并在三十多种视频任务上取得了领先的性能 , 还可实现以中文为核心的百种语音翻译 。
“书生2.0”通用图像模型基于动态稀疏卷积网络 , 可以根据不同的视觉任务自适应地调整卷积的位置以及组合方式 , 从而灵活准确适配不同的视觉任务 。相较于“书生1.0” , “书生2.0”在图像检测等视觉标杆任务上的性能取得重大提升 。以卷积神经网络的方式重新取得图像领域标杆任务的领先性能 , 也为图像大模型提供了新的方向 。
【2022世界人工智能大会|看图更准,能理解视频和做翻译的“书生2.0”来了】“书生2.0”通用视频模型探索掩码学习和对比学习相结合的训练范式 , 突破视频自监督学习的性能瓶颈 , 构建了首个具有体系化动态感知能力的视频大模型 , 全面覆盖基础视频识别、开放视频感知、时空语义解析三大核心领域 。在视频识别、视频时空检测、视频时序定位、视频检索等三十多种视频任务上精度世界领先 。
基于“书生2.0”的通用图像和视频模型 , 可以广泛应对多种视觉任务和多种场景 。在12大类40余种视觉任务中 , “书生2.0”模型支撑取得了领先性能 , 超越了相关领域的国际知名机构 。
在达到优异性能的同时 , “书生2.0”还实现了使用成本更低、更低碳、更环保的目标 。相比达到谷歌的CoCa和微软的SwinV2-G的相似效果 , “书生”使用的计算量远远小于前两者 。
文章图片
文章图片
推出以中文为核心的百语翻译模型
目前大部分开源翻译模型在中文和其他语种之间的翻译时错误率较高 。针对这个痛点 , “书生2.0”积累了大量中文为核心的翻译数据 , 提出了异步多分枝训练技术 , 构建了以中文为核心的百语通用翻译模型 , 一个框架支持161种语言 , 推动中文自然语言处理社区的开放 。
- 数十支开发者团队同台竞技秀“创新”鲲鹏应用创新大赛2022·上海赛区决赛成功举办
- 科大讯飞拿下多语种语言理解领域的硬实力带动人工智能源头
- 30秒延时摄影入场打卡2022世界人工智能大会
- 元宇宙创新探索方阵正式成立暨《2022元宇宙产业图谱》发布
- 2022世界人工智能大会|这场圆桌齐聚中国高校顶尖AI班班主任,探讨人才培养最优模式
- 持续探索大数据、人工智能、云计算…… 中行上海分行加快数字化转型步伐
- 2022数字经济创新创业大赛全国总决赛在江苏徐州举行
- 2022人工智能大会|云宇宙的未来里,女性研究者不可或缺
- 将自己虚拟化,世界人工智能大会带你进入元宇宙逛展
- 上海:2022世界人工智能大会打造虚实融合参会“元”体验