全球首个知识增强千亿大模型“鹏城-百度·文心”发布
AI大模型是人工智能开发、应用的基础设施 , 体现着一个国家的AI技术发展水平 。12月8日 , 鹏城实验室与百度举办新闻发布会 , 联合发布全球首个知识增强千亿大模型——“鹏城-百度·文心”(模型版本号:ERNIE3.0Titan) , 该模型参数规模达2600亿 , 是目前全球最大的中文单体模型 。“鹏城-百度·文心”在机器阅读理解、文本分类、语义相似度计算等60多项任务中取得最好效果 , 并在30余项小样本和零样本任务上刷新基准 。

文章图片
文章图片
中国工程院院士、鹏城实验室主任高文(左) , 百度首席技术官、深度学习技术及应用国家工程实验室主任王海峰联合发布“鹏城-百度·文心”
中国工程院院士、鹏城实验室主任高文在发布会上表示 , 大模型对于整个科学的发展、社会的发展、创新的发展都是非常重要的工具 。运用这个工具 , 可以让更多行业受益于人工智能的赋能 , 这对人工智能的发展是一个福音 。
为解决“鹏城-百度·文心”大模型应用落地难题 , 百度团队首创大模型在线蒸馏技术 , 模型参数压缩率可达99.98% 。压缩版模型仅保留0.02%参数规模就能与原有模型效果相当 , 更有利于产业大规模应用 。本着开源开放的理念 , 该模型代码近期会在OpenI启智社区开源 , 依托“鹏城云脑Ⅱ”对外开放 , 助力科技创新 , 推动产业发展 。
“鹏城-百度·文心”大模型的成功研发 , 源于鹏城实验室与百度共同成立的“鹏城-百度自然语言处理联合实验室” 。“鹏城-百度·文心”大模型基于鹏城实验室的算力系统“鹏城云脑Ⅱ”和百度飞桨深度学习平台的支持 , 解决了超大模型训练的多个公认技术难题 , 实现了训练速度大幅提升、效果更优 。“鹏城云脑Ⅱ”是自主研发的国内首个E级AI算力平台 , 曾在多个国际性能测试比赛中夺冠;飞桨是我国首个自主研发的深度学习开源开放平台 , 创建了端到端自适应分布式训练框架 , 实现多硬件支持 , 并行效率高达90% 。
文章图片
文章图片
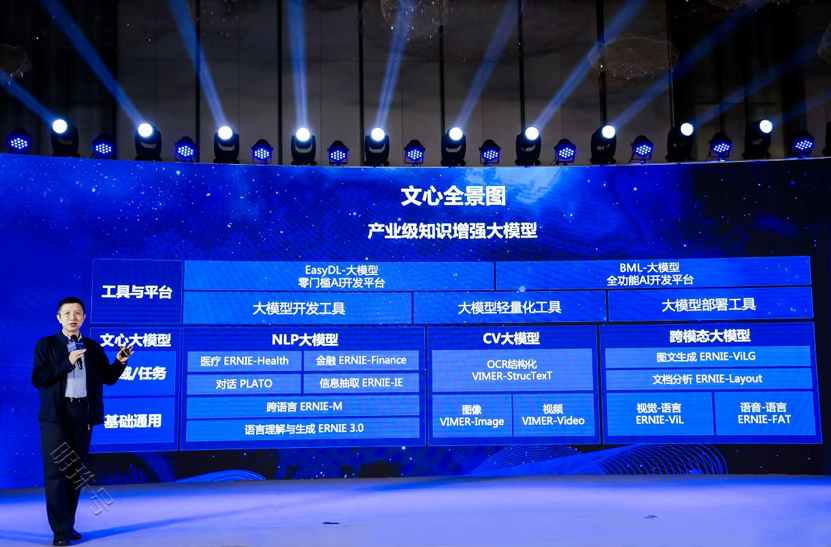
百度首席技术官、深度学习技术及应用国家工程实验室主任王海峰发布百度产业级知识增强大模型“文心”全景图
当日发布会上 , 百度产业级知识增强大模型“文心”全景图也首次亮相 。王海峰介绍 , 最新的产业级知识增强大模型“文心”全景图 , 既包含基础通用的大模型 , 也包含面向重点领域、重点任务的大模型 , 以及丰富的工具与平台 , 有助于推动技术创新和产业发展 。
【全球首个知识增强千亿大模型“鹏城-百度·文心”发布】目前 , 百度“文心”通过百度飞桨平台陆续对外开源开放 , 并大规模应用于百度搜索、信息流、智能音箱等产品 , 并通过百度智能云赋能工业、能源、金融、通信、媒体、教育等众多行业 。在金融领域 , 通过百度“文心”大模型赋能 , 同时结合百度全流程AI开发平台BML提供模型再训练的能力 , 基于定制的保险合同条款“智能解析模型” , 不仅能够完成一份合同内近40个类目条款的智能分类 , 根据计算 , 业务员处理单份合同文本的时长缩短到1分钟 , 速度提升了几十倍 。百度智能云的“智能客服”也基于百度“文心”提升了服务的精准性 , 目前已在中国联通、浦发银行等国内众多企业中得到应用 。(完)
- 遍知教育赋能升级或将打破知识付费行业格局
- 哈啰虎年限量款电动车亮相号称全球10台只送不卖
- 长安福特蒙迪欧在中国市场的“全球化”
- canalys公布2021年全球个人电脑市场数据
- 微软、动视暴雪并购电话会实录:元宇宙、云游戏,开启新一轮全球硬科技战事
- Canalys:苹果2021年四季度重夺全球手机销量第一,小米第三
- 中国再次领先全球,利用二氧化碳就能发电,颠覆140年发电方式
- 机构:中国市场需求强劲,去年四季度苹果手机出货量全球第一
- 刚刚,高新区首个航天产业项目成功签约!
- 微软687亿美元收购动视暴雪|微软687亿美元收购动视暴雪(晋身全球第三大游戏公司)