routerz-loss模型的重要性
稀疏模型在深度学习领域发挥着越来越重要的作用 。对于给定的token或样本 , 它可以只激活模型的一小部分 , 从而在拥有很大的参数量的同时也能做到计算友好 。但是 , 如何可靠地训练这类模型依然是一个需要解决的问题 。在这篇文章中 , 来自谷歌的BarretZoph、IrwanBello、WilliamFedus、JeffDean等研究者给出了一份「高效稀疏专家模型设计指南」 。
文章图片
文章图片
稀疏专家神经网络展示了纯规模的优势 , 并为当今常用的静态神经网络架构提供了一种有效的替代方案 。稀疏专家网络不是对所有输入应用相同的参数 , 而是为每个输入动态选择使用哪些参数 。这允许网络极大地扩展参数的数量 , 同时保持每个token的FLOPs大致不变 。这些方法的采用已经带来了SOTA翻译模型、4-7倍的预训练加速 , 以及仅使用1/3的训练成本就能达到GPT-3级的one-shot性能 。尽管参数数量惊人 , 但稀疏模型将训练大型神经网络的碳足迹降低了一个数量级 。然而 , 困难依然存在 。
【routerz-loss模型的重要性】Fedusetal.(2021)观察到 , 与之前的SOTA方法(Raffeletal.,2019)相比 , 稀疏1.6T参数模型实现了4倍的预训练加速 , 但在SuperGLUE等常用基准上进行微调时 , 却落后于较小的模型 。在Artetxeetal.(2021)中 , 研究者在域外数据上对MoE语言模型进行了微调 , 并观察到了相似的差距 。
为了解决这一问题 , Switch-XXL模型被提出 , 该模型参数较少 , 但计算占用空间增加到原来的8倍(FLOPs大约等于最大的T5模型) , 在自然语言理解任务上的性能有所提高 。然而 , 必要的预训练受到先前在小规模研究中未检测到的训练不稳定性的阻碍 。这些不稳定性后来在其他稀疏模型中被识别出来 。这些结果揭示了参数和计算的必要平衡 , 但如何可靠地训练这种模型依然是一个待解决的问题 。
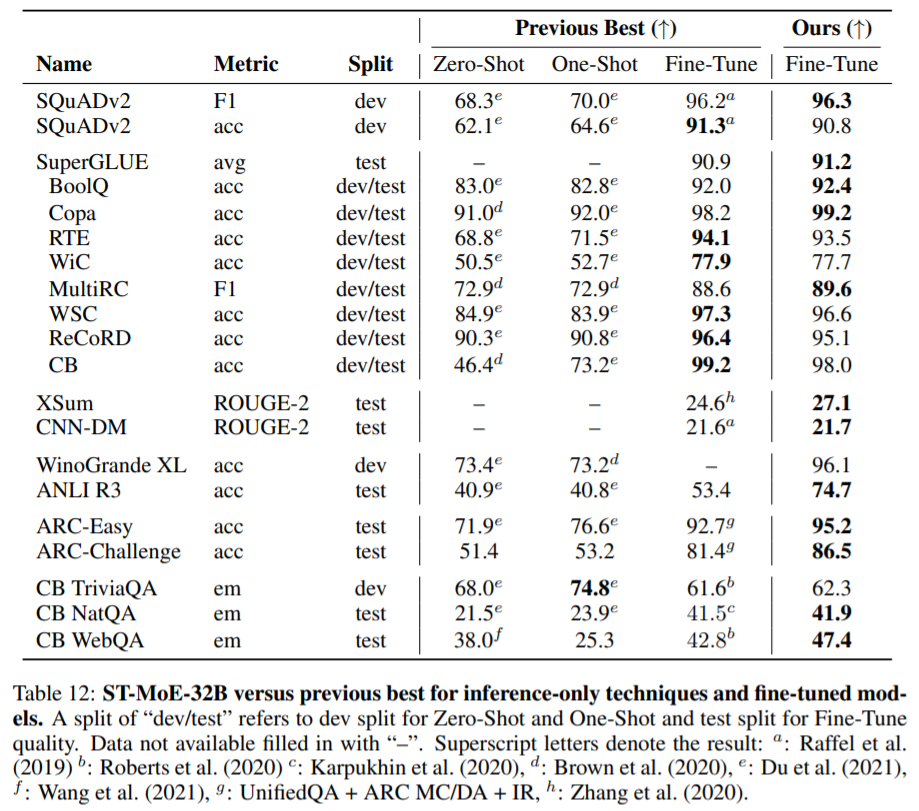
这篇论文的目的就是提高稀疏模型的实用性和可靠性 。他们研究了这两个问题 , 并给出了设计指南 。最后 , 他们将稀疏模型的参数缩放到269B , 其计算成本与32B密集编码器-解码器Transformer(稳定、可迁移的Mixture-of-Experts、ST-MoE-32B)相当 。这是稀疏模型首次在迁移学习中实现SOTA性能 , 跨越了一系列不同的任务 , 包括推理(SuperGLUE、ARCEasy、ARCChallenge)、摘要(XSum、CNN-DM)、闭卷问答(WebQA、NaturalQuestions)和对抗式构造任务(Winogrande、ANLIR3) 。
文章图片
文章图片
本文的贡献可以概括如下:
1、开展了一项关于稳定性技术的质量-稳定性权衡(quality-stabilitytrade-offs)大规模研究;
2、引入了routerz-loss来解决稳定性问题 , 同时略微提高了模型质量;
3、给出了关于稀疏和密集模型的微调分析 , 揭示了二者对批大小和学习率的不同超参数敏感性;他们发现 , 糟糕的超参数导致密集模型上几乎没有微调增益 , 尽管预训练有很大的加速;
4、给出了分布式环境下设计Pareto高效稀疏模型的架构、routing和模型设计原则;
5、给出了追踪跨专家层的tokenrouting决策的定性分析;
6、训练出了一个269B稀疏模型 , 在一组不同的自然语言基准上实现了SOTA性能 。
routerz-loss
稳定神经网络最成功的方法之一是对激活的约束和梯度 。一种流行的方法是在通过深度网络反向传播时 , 裁剪梯度范数来弥补爆炸梯度 。
在这篇论文中 , 研究者使用Adafactor优化器是因为它的内存效率(尽管最近推出的8位优化器(Dettmersetal.,2021)可能会提供更好的trade-off) 。Adafactor使用更新裁剪(updateclipping) , 而不是梯度裁剪(gradientclipping) , 其中对权重的更改被限制在一定的范数以下 。他们尝试将更新裁剪收紧到更小的值 。
- 全球首个以赛事命名的卫星——“大运号”卫星如何赋能成都大运会,与城市同发展?
- 宇宙的边缘在哪里?光到达地球的边缘在哪里呢
- g胖:那些谈元宇宙的人大多自己都不清楚
- 满10元减9元、大转盘抽奖、好物0元购…有这个银行APP的荆门人恭喜了
- valve:区块链技术本身是精妙的
- 你觉得手机上的内存,多大才够用?
- 全球首个以赛事命名的卫星将在成都发射
- 紫色西红柿,抗氧化剂和花青素的含量都大大提高
- 《张朝阳的物理课》带你理解热力学基本定律
- 8亿活跃买家的拼多多,仅靠低价或已经不够