从做“选择题”到做“判断题”,科大讯飞让机器解锁理解思考能力
本文转自:上游新闻
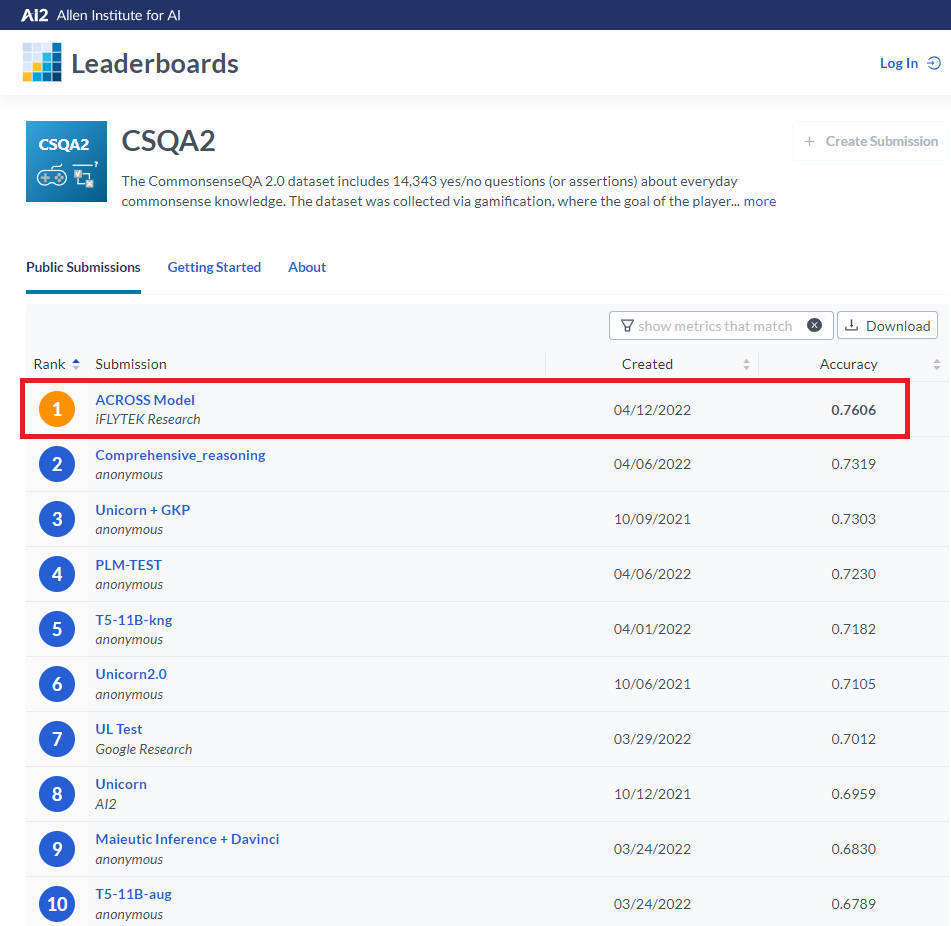
近日 , 由科大讯飞承建的国内首个认知智能国家重点实验室 , 以76.06%的成绩登顶常识推理挑战赛CommonsenseQA 2.0 , 刷新世界纪录 , 在让机器“能理解、会思考”上迈出一大步 。
CommonsenseQA 2.0是艾伦人工智能研究院(Allen Institute for AI)于2021年主导发布的国际常识推理评测数据集 , 旨在评估机器对常识知识的理解及掌握水平 , 吸引了包括Allen Institute for AI、华盛顿大学等众多国际顶尖机构参与挑战 。科大讯飞首次参赛 , 即创新性地提出ACROSS模型 , 以全新深度学习算法绝对优势 , 刷新机器常识推理水平世界纪录 。
文章图片
文章图片
当前 , 典型的阅读理解模型所关注的问题类型主要是事实类问题 , 这类型的问题答案往往能直接在原文中找到 , 然而如何基于常识和背景知识进行推理以获得答案是一个巨大的挑战 。
该大赛正是为了训练机器像人一样 , 基于先验知识结合现实情况作答能力而设置的数据集 。比如 , 当被问到:“我可以站在河上的什么地方看水流而不会弄湿自己?”这种知识对人类而言似乎很好理解 , 但是如何让机器学会常识及背景知识并进行准确推理 , 仍然是一个巨大的挑战 。
据了解 , CommonsenseQA 2.0是一个二元分类数据集 , 包含14343个问题 , 主要分为训练、开发、测试集 , 需要判断常识性陈述是对还是错 。1.0版本所考察的问题 , 是基于现有常识知识库ConceptNet中的知识三元组构建的 , 这使得机器在处理该任务时 , 有能直接聚焦参考的知识 。
相比较1.0的“选择题” , 2.0“判断题”挑战难度更高 , 仅给定一个主题实体或概念、一个常识类关系 , 让人类以自然语言的方式去构造机器较难掌握的常识知识 。
该构造方法所构造的常识推理问题具有庞大的想象空间 , 大部分在当前知识库中并未覆盖 , 这无疑显著增加了机器处理该类问题的难度 。目前以科大讯飞为代表的中国人工智能力量在常识推理领域中已有很大的进步 , 但是仍远低于人类94.1%的水平 , 可见在常识性推理方向仍有很大挑战和进步空间 。
本次由科大讯飞承建的认知智能国家重点实验室团队 , 创新提出的面向常识知识推理的ACROSS(Automatic Commonsense Reasoning on Semantic Spaces)模型 , 该模型实现了统一语义空间下外部知识的有效融合 , 显著改进了超大规模预训练模型所存在的问题 , 在CommonsenseQA 2.0任务上取得76%的准确率 。
【从做“选择题”到做“判断题”,科大讯飞让机器解锁理解思考能力】该评测的常识推理问题 , 不论在ConceptNet等知识库 , 或者互联网上 , 都较难找到直接的答案 。从人类进行常识知识运用及推理的习惯出发 , 对于一个复杂的问题 , 首先需要查阅相关知识库或典籍 , 其次会借助互联网搜索去查找相关信息 。ACROSS模型正是借鉴该思路 , 充分收集知识库、互联网相关信息 , 在统一的语义空间中进行融合处理 , 最后赋予超大规模预训练模型更强的知识输入 , 实现准确的常识知识推理 。该方法结果也一定程度上证明了机器已初步具备对于各类复杂文本信息及知识的深入理解及运用能力 。
- 特殊的“安全守门员”助力疫情防控
- 英雄凯旋!来看看“神十三”背后的哈工大力量
- 官宣!“长江头条”微信小程序正式上线
- 企业创新志 | 开立医疗:“深圳造”彩超守护航天英雄健康
- “穗康”小程序新增抗原检测结果上报专区
- 合肥通信技术护航“神舟”回家
- 神舟十三号太空出差183天,这些“山东造”保驾护航
- 从“神五”到“神十三”,这两名黑龙江人四次圆梦太空……
- 汕头2个项目获省科技奖一等奖,分别来自“超声”和“光华”
- 神舟十三号返航,南航人持续助力“保驾护航”