消息队列上云挑战与方案:腾讯云的 Apache Pulsar( 二 )
3遇见ApachePulsar
如果使用传统的消息队列上云 , 要解决上述问题需要费一番功夫 。通过调研 , 我们发现为云原生打造的下一代分布式消息系统ApachePulsar能很好地解决上述的大部分问题 。下面针对上述各种挑战 , 我们从ApachePulsar具备的能力做下针对性概述 。
支持秒级平滑扩容
ApachePulsar支持云原生环境 , 可以充分利用云原生环境的弹性能力 , 达到自动、无感知的扩容 , 按需使用 , 不影响上层业务 。ApachePulsar使用BookKeeper作为数据存储层 , 而BookKeeper原生避免数据倾斜问题 。
ApachePulsar上层Broker无状态 , 原生支持平滑扩容 。当流量突发增加时 , 只需要增加一个Broker , 然后等待部分Topic重新分配到新的Broker上 , 流量就会自动迁移到新的Broker上 。整个过程只涉及元数据的修改和Topic分配的计算 , 实现秒级自动迁移 。
具备海量分区支撑能力
【消息队列上云挑战与方案:腾讯云的 Apache Pulsar】在云上 , 海量分区是常见问题 。假设客户有100万个分区 , 如果把每个分区的元数据信息都保存起来 , 那总体数据量会有几百MB , 光是下载这么多的数据都需要很多时间 。
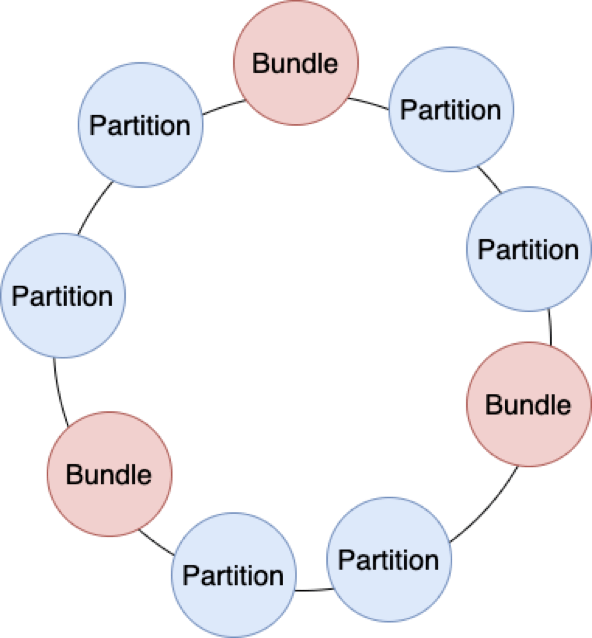
ApachePulsar没有完全解决所有问题 , 但已经具备支持海量分区的能力 。ApachePulsar抽象了Bundle的概念 。Bundle的元数据保存在ZooKeeper 。每个分区落在哪个Broker上 , 这种关系信息不会直接保存起来 。ApachePulsar使用一致性哈希 , 把Bundle作为哈希环中的节点 , 让所有的分区散列上去 。我们只需保存Bundle与Broker之间映射关系的信息即可;分区与Bundle之间的关系是固定的 , 可以通过散列动态计算出来 , 不需要保存每条关系 。
文章图片
文章图片
如此一来 , 我们需要存储的元数据就有几个量级的下降 。在切换Broker时 , 基于一致性哈希的优势 , 分区再平衡只会涉及到部分变动 , 可以迅速重新进行分配 。
4ApachePulsar在腾讯云上的实践
通过调研后 , 我们决定基于ApachePulsar打造一款新的消息队列——TDMQ , 开启Pulsar在腾讯云上的实践之路 。下面和大家分享下ApachePulsar在腾讯云上的实践经验 , 探究Pulsar如何快速适配云原生环境
云原生下的平滑扩容
我们利用ApachePulsar支持云原生环境进行平滑扩容 。常见的扩容场景分为几种情况:
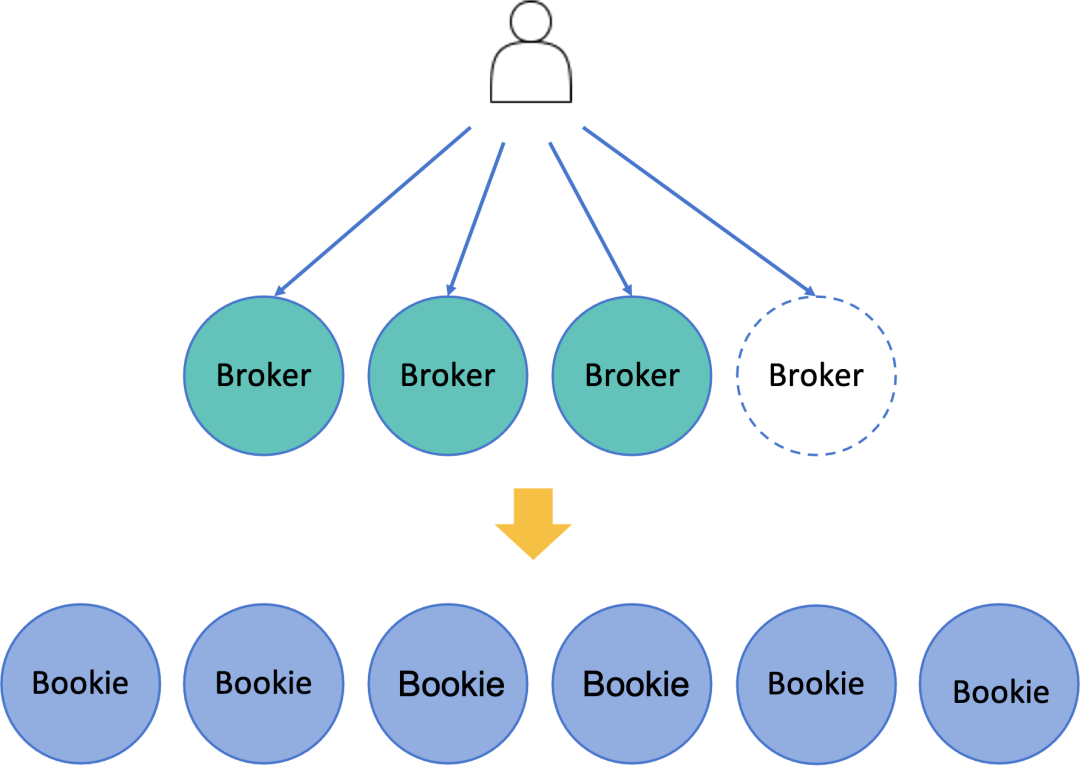
a)当分区数量远大于Broker数量时 , 新增Broker , 分区用一致性哈希(hash)方式自动迁移Topic到新的Broker , 然后新的Broker就可以对外提供服务 , 分担压力 。
b)当分区数量少于Broker数量时 , 增加分区 , 让流量分布到更多Broker上 , 从而实现平滑扩容 。
文章图片
文章图片
数据倾斜与存储层扩容
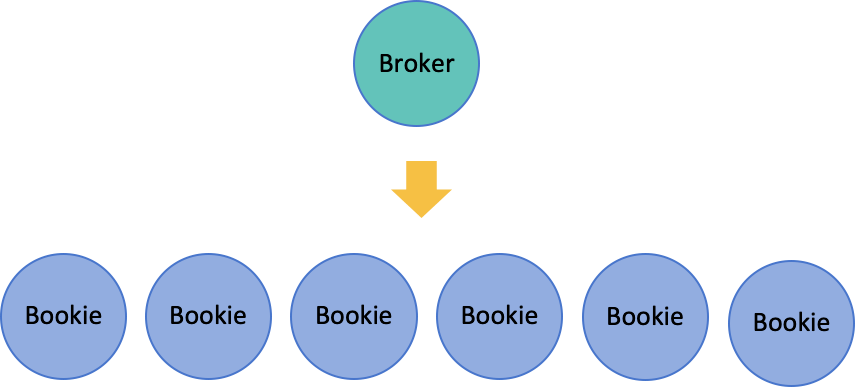
Broker不保存数据 , Broker通过BookKeeperClient把数据保持到BookKeeper集群中 , 每个节点我们称为Bookie 。最终还是无法避免Bookie是有状态的 , 问题又回到了原点 , 有状态的Bookie又如何实现平滑扩容呢?
首先 , 我们需要了解ApachePulsar的存储机制 。Pulsar使用Quorum机制来保证数据的一致性和高可用 。当Pulsar持久化一条消息时 , Broker使用BookKeeperclient同时并行写入多个Bookie节点 , 根据消息的Ack数 , 来判断有多少数据写入成功 。ENSEMBLESIZE(E):可用Bookie的数量WRITEQUORUMSIZE(QW):并行写入消息的Bookie数量QUORUMSIZE(QA):Ack消息的数量
文章图片
- 冬奥在即!“AI教练”、滑雪机器人,沪上高校科技助力“冰雪精灵”!
- 线上新书发布!云上带你了解有关“冬奥”的那些事儿
- 和平精英特斯拉roadster新皮肤哪天出(和平精英特斯拉roadster新皮肤上线时间分享)
- 阴阳师SP面灵气什么时候上(阴阳师SP面灵气上线时间分享)
- 钢琴陪练app排行榜上的小马AI陪练怎么样
- 毕节人,囤年货啦
- 冬奥防疫“黑科技”上线,45分钟完成空气气溶胶病毒检测
- 怎么在手机上打印社保缴费明细单(手机打印社保缴费明细方法详解)
- 微信朋友验证消息是怎么回事(?微信查看好友添加来源步骤)
- 永劫无间公测三排上分阵容怎么搭(永劫无间公测三排上分阵容完美搭配指南)