消息队列上云挑战与方案:腾讯云的 Apache Pulsar( 三 )
文章图片
如果Bookie的数量大于QW的值 , 数据会以条带化的方式落到不同节点上 , 过程如下图所示:

文章图片
文章图片
第一条消息 , Broker会同时写入Bookie1、Bookie2、Bookie3 。
第二条消息 , Broker会同时写入Bookie2、Bookie3、Bookie4 。
第三条消息 , Broker会同时写入Bookie3、Bookie4、Bookie5 。
第四条消息 , Broker会同时写入Bookie4、Bookie5、Bookie6 。
...
这种条带化写入的好处显而易见 , 既能充分利用每个磁盘上的IO , 还能让数据存储近似均匀 , 避免出现数据倾斜问题 。当增加新Bookie节点后 , 无需等待数据迁移就可以对外提供服务 , 整个过程非常平滑 。
海量分区:降低和去除ZK依赖
海量分区是我们要解决的一个重要问题 。如上所述 , Pulsar抽象的Bundle的概念能很好地帮助我们解决上云过程中遇到的海量分区管理问题 。但ledger、cursor等其他元数据还是存储在ZooKeeper中 。当分区数量达到百万时 , ZooKeeper会不堪重负 。因此 , 我们基于Pulsar做了一些改进——降低和去除Broker对ZooKeeper的依赖 。
ApachePulsarBroker对ZooKeeper的依赖主要包括以下几个方面:负载状况生产、消费Policy存储Leader节点选举
通过对依赖的分析和梳理 , 我们确定了降低和去除对ZooKeeper依赖的两步目标:
a.降低Broker对ZooKeeper的依赖 。即使ZooKeeper挂掉了 , Broker至少在一段时间内不会受到很大的影响 , 可以继续提供读写服务 , 等待ZooKeeper的恢复 。
b.完全去除对ZooKeeper的依赖 。将元数据全部保存到Bookie , 不再依赖ZooKeeper存储数据 。
具体地 , 我们对代码做了一些改动 , 如:在ZooKeeper挂掉、本地缓存超时的情况下 , 让本地的缓存快照不过期 , Broker保持当前元数据不变 , 继续使用缓存中的元数据 。在写入过程中 , 如果Ledger承载的entry数量已经超过了限制的大小 , ApachePulsar会关闭当前Ledger并重开一个Ledger 。我们优化后 , 在这种情况下 , Broker暂时不关闭当前Ledger , 而是继续写入 , 从而避免访问ZooKeeper 。使用外部存储保存负载状况等数据 。
增强原生异地复制能力 , 提供强一致方案
有些用户的业务场景对高可用的要求非常高 , 需要同城多机房或者两地三中心的异地多活 。Pulsar本身有相应的异地复制能力 , 但属于异步复制 。异步复制就要看用户对RTO、RPO(RecoveryPointObjective , 恢复点目标)的容忍程度 , 如果要求100%可靠 , 一条消息都不能丢 , 那异步复制不能满足要求 。
另外 , 异步复制即使为全量复制 , 为了保证消息顺序 , 同一时间我们通常只会使用一个中心 , 这样整体资源利用率最多为50% , 资源使用率不高 。另外 , 无法保证灾备中心何时能接管流量 , 接管后所有业务是否正常运行 。因此 , 我们提供了强一致的方案 。
文章图片
文章图片
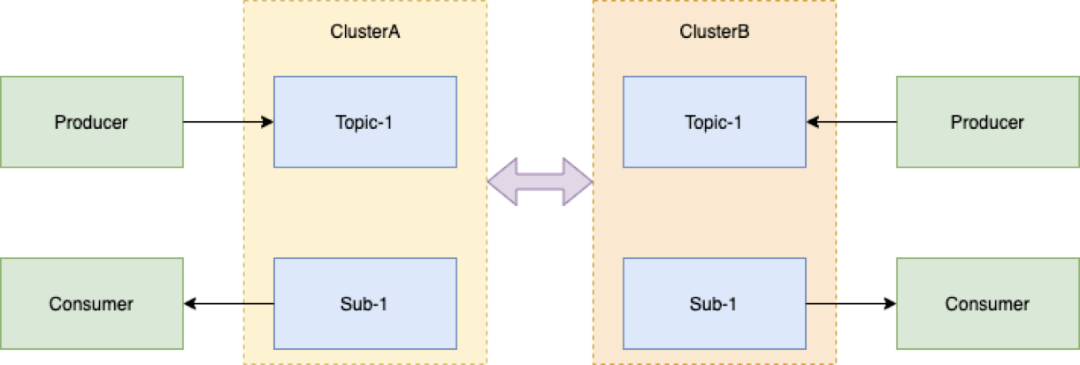
1.同城跨机房
Broker跨机房 。多数据中心之间地位均等 。正常模式下 , 多数据中心协同工作 , 并行为业务提供访问服务 , 充分利用资源 。一个数据中心发生故障或灾难 , 其他数据中心正常运行 , 立即对关键业务或者全部业务实现接管 , 达到互备效果 , 使上层业务不会有明显的感知 。
文章图片
文章图片
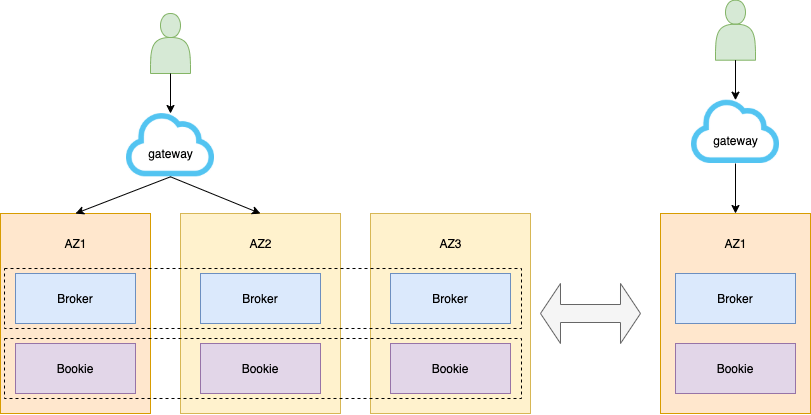
2.三中心高可用
跨地域场景 , 分为生产中心、同城容灾中心、异地容灾中心 。当双中心由于自然灾害等原因而发生故障时 , 异地灾备中心可以用备份数据恢复业务 。
- 冬奥在即!“AI教练”、滑雪机器人,沪上高校科技助力“冰雪精灵”!
- 线上新书发布!云上带你了解有关“冬奥”的那些事儿
- 和平精英特斯拉roadster新皮肤哪天出(和平精英特斯拉roadster新皮肤上线时间分享)
- 阴阳师SP面灵气什么时候上(阴阳师SP面灵气上线时间分享)
- 钢琴陪练app排行榜上的小马AI陪练怎么样
- 毕节人,囤年货啦
- 冬奥防疫“黑科技”上线,45分钟完成空气气溶胶病毒检测
- 怎么在手机上打印社保缴费明细单(手机打印社保缴费明细方法详解)
- 微信朋友验证消息是怎么回事(?微信查看好友添加来源步骤)
- 永劫无间公测三排上分阵容怎么搭(永劫无间公测三排上分阵容完美搭配指南)