走进高维空间之“维度魔咒”,所有的“邻居”都去哪了?( 二 )
文章图片
文章图片
通常情况下 , 我们会将产量(即响应变量)作为一个额外的轴/维度进行可视化 , 但我在这里没有这样做 , 因为我们只能将三个维度可视化化 。
比方说 , 现在是春天 , 我们正在种植新的西红柿作物 。我们有土壤的硝酸盐水平和pH值 , 而且我们对预期的降雨量有一个很好的概念 。我们把这个新作物表示为下面的红点 。

文章图片
文章图片
利用原来三个点的作物特性和产量 , 我们如何估计新的红色点的产量?有一种方法 , 叫做(单)近邻法 , 就是用原来三个点中最接近的作物产量来估计 。我们会期望最近的点有大致相似的降雨量和土壤成分 。看起来橙色点离红色点最近(产量为40000) 。然而 , 从一个数据点推导出估计 , 不觉得有点不靠谱吗?也许与橙点相关的产量是一个意外 , 同样的特性在其他年份产生的产量可能会低得多 。只有3个数据点 , 没有什么操作空间 , 但如果有数百个数据点呢?

文章图片
文章图片
现在 , 加入红点所代表的新作物 。

文章图片
文章图片
同样 , 我假设我们知道所有蓝点的作物产量 , 并希望利用这些信息来估计红点的作物产量 。我们是否应该再次采用K-近邻算法? 下面 , 我们找出离红点最近的20个“邻居” 。

文章图片
文章图片
为了估计红点的作物产量 , 取这20个近邻的作物产量的平均值似乎很合理 , 对吗?在这个例子中 , 我们只是在三维空间中运算 , 但这个方法可以推广到任何维度 。
我们如何定义 "最近的"?普通的欧几里得距离?还是像马氏距离( Mahalanobis distance )这样更细微的东西(它包含了不同预测因子之间的变化和关系)?这些问题都很重要(而且超级有趣) , 但答案与我们现在所要讨论的无关 , 所以我将把它们放在以后的文章中 。
让我们继续向前进:高维空间!
邻居们 , 你们好!
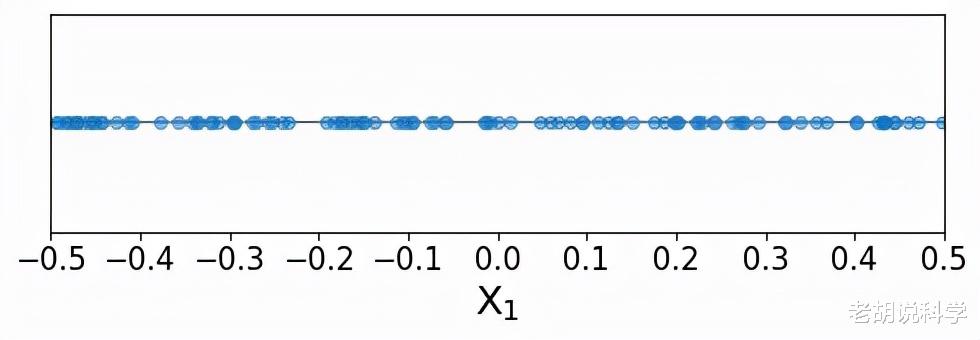
在接下来的部分中 , 我们将从有趣的应用实例(例如病人、家庭、农作物)中“撤退” , 进入一个简化的空间 。想象一下 , 我们正在处理只有一个预测变量和一个响应变量的数据;因此 , 预测空间只有一个维度 。我们还可以想象 , 预测变量的值是沿着预测变量的范围均匀分布的 。为了简单起见 , 我们使用一个只能在-0.5和0.5之间取值的预测器 , 这样 , 预测器的范围是一个单位长度 。
同样 , 假设我们有一组数据点的预测值和响应值(称为训练数据点 , 因为这些是用来训练K-近邻模型的点) 。让我们用蓝色来说明这些训练数据点 。
文章图片
文章图片
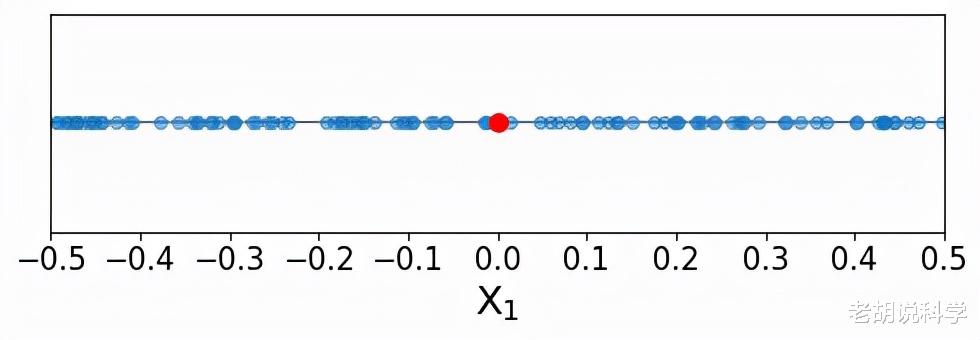
我们可以看到 , 训练点似乎是沿着单一预测器的所有可能值均匀分布的 。现在 , 我们要预测一个新的点(称为索引点)的响应值 , 下面用红色表示 。
- 上海咖啡文化再添新空间:星巴克1971客厅、专星送新功能等首发美团
- 首发美团 星巴克推1971客厅专属空间服务
- 以数字创新焕新第三空间 星巴克1971客厅等新功能在美团首发
- 星巴克全面上线美团外卖 深圳等地可线上预订专属空间服务
- 对话学界和业界 走进元宇宙的平行世界
- 走进深蓝|山东省智慧海洋大数据平台在青岛揭牌
- 线上线下双“IQ”赋能,凯迪拉克LYRIQ打造更高维度的用户互联
- 标题:登峰·匠筑 依循“产品之道”,臻致空间美学
- 崩坏3无尽漩涡|崩坏3无尽漩涡攻略(边际空间无尽漩涡高分打法推荐)
- 极空间推出新款四盘位nas——新z4