走进高维空间之“维度魔咒”,所有的“邻居”都去哪了?( 四 )
这里的基础数学其实很简单 , 真正的精彩在最后 。
让我们用一个例子来说明这个问题吧 , 记得农作作物例子吗? pH值的范围是0-14 。如果我索引点的pH值为7 , 那么就要在一个维度上包括pH值为6.25-7.75的训练点(直觉上似乎是合理的 , 对吗?) , 在两个维度上包括4.6-9.4(这合理吗?) , 在三个维度上包括3.55-10.45(这似乎开始离谱了) 。将这些点称为邻居还有意义吗?
延伸
在应用统计学中 , 使用几十个、几百个、甚至几千个预测因子是很常见的 。如果在三个维度中 , 每个预测器的范围有近50%是用来捕捉10%的训练数据的 , 那么在10个维度中呢?100个维度呢?
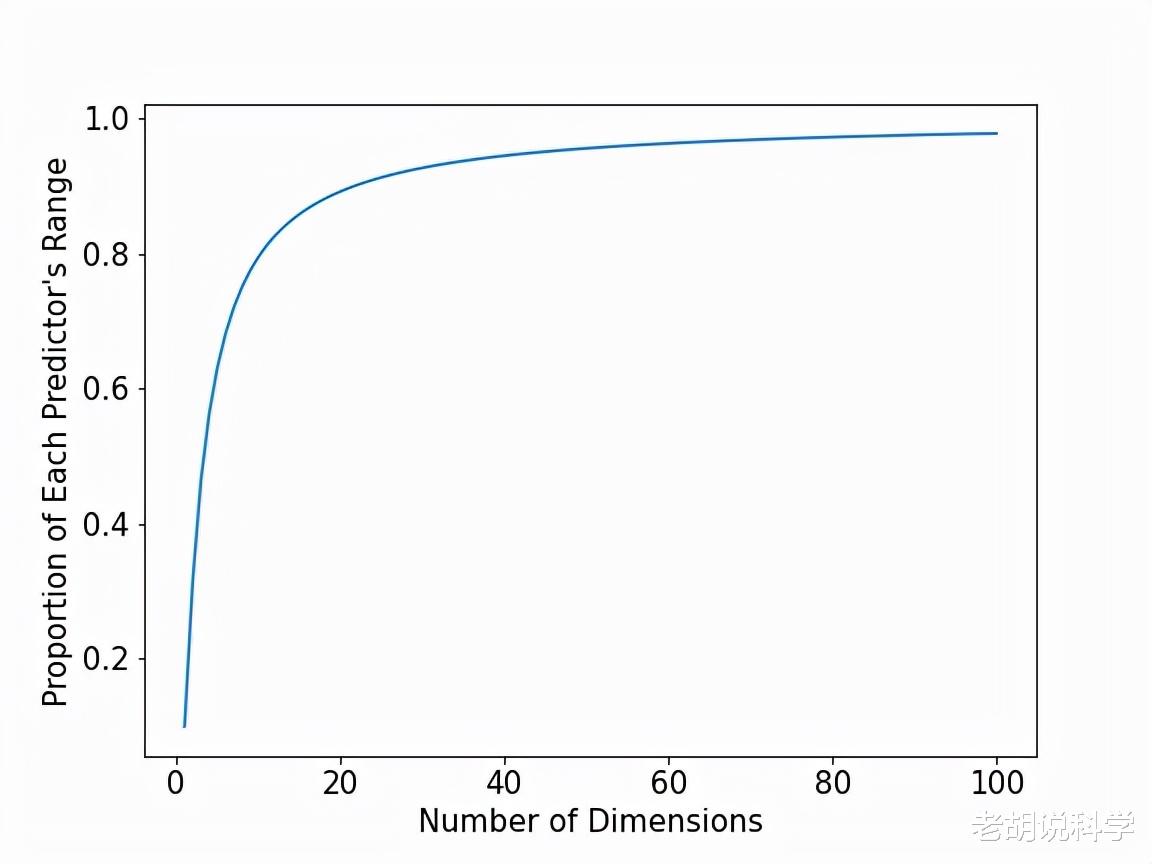
下面的图对1到100个维度之间的每一个维度回答了这个问题 。具体来说 , 我们把维度(即预测器)的数量放在X轴上 , 把每个预测器的范围比例(捕获10%的训练数据所需)放在Y轴上 。
文章图片
文章图片
在图的最左边 , 我们看到了在一维、二维和三维方面的情况 。然而 , 当达到10个维度时 , 几乎需要每个预测器的80%的范围!在50个维度时 , 需要95%的预测器范围 。到了100个维度 , 需要98%!
我们的目标是确定那些预测值与索引点尽可能相似的训练点 。在这些更高的维度上 , 几乎把预测器的任何值的点视为邻居 , 并将使用它们来估计索引点的响应值 。在我们设计的具有均匀分布的预测因子的例子中 , 应用K-近邻算法在一个维度上似乎是完全合理的 , 但在更高的维度上很快就会变得离谱 。真实的数据集不会和我们探索的数据集一模一样 , 但这种需要进一步深入预测器空间来寻找附近点的想法依然存在 。
所有的邻居都去哪儿了?
让我们来探讨一个稍微不同的问题 。之前 , 我们调查了在每个维度上取多少范围才能捕获10%的训练数据 。现在 , 让我们看看 , 如果把邻居的边界限制在每个预测器范围的10% , 能找到多少个邻居 。在K-近邻算法的背景下 , 在空间上与索引点接近的训练点似乎很适合为索引点的响应值的估计提供信息 。在一个维度上 , 一个包括10%的单一预测者范围的邻域包含了10%的训练数据 。在更高的维度上会发生什么?让我们来看看 。
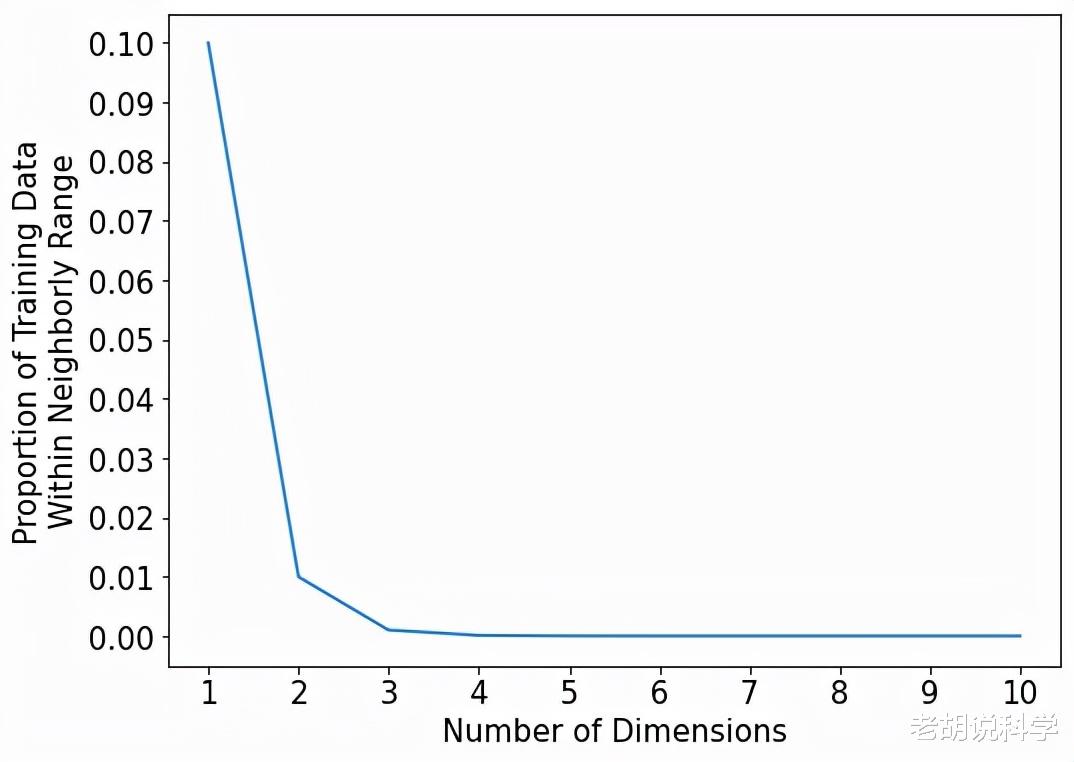
下面的图在X轴上显示了从1到10的维度 , 在Y轴上显示了覆盖每个预测器范围的10%的邻域所捕获的训练数据的比例 。
文章图片
文章图片
所有的邻居都去哪了?同样 , 在一个维度上 , 邻域覆盖了10%的训练数据 。在二维 , 只有1%的训练数据! 如果我们把一个索引点的邻域定义为覆盖每个预测者范围的10% , 那么一个10维的邻域将只包括训练数据的0.00000001% 。
让我们用训练数据点的实际数量来重新定义这些数字 , 而不是百分比和比例 。比方说 , 有100,000个训练数据点 。这意味着 , 10维邻域平均来说 , 甚至没有捕捉到一个数据点(它将捕捉到0.0001个数据点) 。这意味着 , 平均而言 , 每一万个邻域中 , 我们只能捕捉到一个邻域!这意味着很多空的邻域 。这就是大量的空邻居!
因此 , 用一个直观合理的邻域大小(覆盖每个预测因子范围的10%) , 在更高维度上基本上没有邻域 。而这里只到了10维!如果是100维 , 100万维呢?
你已经进入了一个新的领域 。进入了没有邻居的地方! 邻居们都去哪儿了?为什么这些空间如此空旷?这些都是贯穿于高维空间的永恒的问题 , 这些问题引起了(并困扰着)许多统计学家 , 被精致地称为维度诅咒!
- 上海咖啡文化再添新空间:星巴克1971客厅、专星送新功能等首发美团
- 首发美团 星巴克推1971客厅专属空间服务
- 以数字创新焕新第三空间 星巴克1971客厅等新功能在美团首发
- 星巴克全面上线美团外卖 深圳等地可线上预订专属空间服务
- 对话学界和业界 走进元宇宙的平行世界
- 走进深蓝|山东省智慧海洋大数据平台在青岛揭牌
- 线上线下双“IQ”赋能,凯迪拉克LYRIQ打造更高维度的用户互联
- 标题:登峰·匠筑 依循“产品之道”,臻致空间美学
- 崩坏3无尽漩涡|崩坏3无尽漩涡攻略(边际空间无尽漩涡高分打法推荐)
- 极空间推出新款四盘位nas——新z4