算法相对论|复旦教授邱锡鹏:神经网络还远远谈不上有意识
本文转自:澎湃新闻
今天我们常常谈及“AI赋能百业” , 这其中隐含的对人工智能的信心并非寻常 , 且实际上非常新潮 。
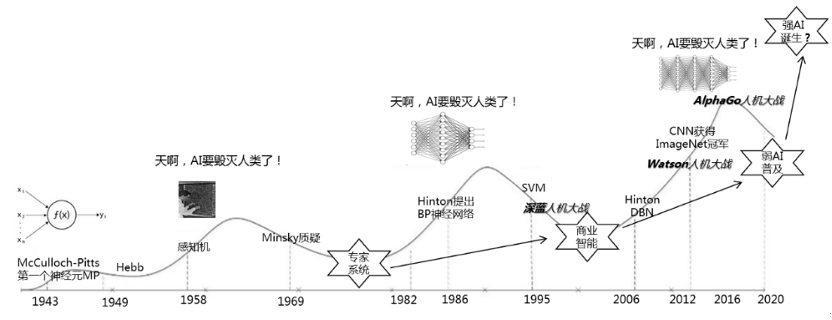
2012年 , “深度学习之父” Geoffrey Hinton带领的团队一鸣惊人夺得ImageNET图像识别大赛冠军 。深度学习表现出远超传统方法的效果 , 由此开启了工业界人工智能应用研究的热潮 , 至今不到十年 。
翻看人工智能的发展史 , 人类对AI的想象似乎常在过度神化与无尽悲观之间作摆锤运动 。有如2016年AlphaGo战胜人类围棋世界冠军的高光时刻 , 人类涌起对AI的无尽想象 , 也有各种“AI不灵”的落地困难 , 前景低迷 。
文章图片
文章图片
以此观察学术界近期的两个热议话题似乎也有所写照:一个是OpenAI首席科学家Ilya Sutskever发推文表示大型神经网络可能有点意识了 , 一个是纽约大学名誉教授Gary Marcus发文《深度学习要碰壁了》 。
一个是似乎看到了人工智能构造人类智能的曙光 , 一个则觉得这套要不灵了 。两个都“有幸”得到了2018年图灵奖得主Yann LeCun的嘲讽 。
要讨论这个话题 , 有一个非常简单的基础知识要了解 。粗略地说 , AI算法语境中的神经网络是对人类大脑运作方式的模仿 , 深度学习则是三层或更多层的神经网络 。
所以在人工神经网络(Artificial Neural Networks)发展之初就有个朴素的想法:人脑有数十亿个神经元和数万亿个突触 , 人工神经网络越接近这样的复杂度就越可能实现人类智能 。
复旦大学计算机科学技术学院教授邱锡鹏在接受澎湃新闻(www.thepaper.cn)采访时也多次提到Hinton说过的“神经网络是目前唯一证明了可以产生智能的模型 。”在邱锡鹏的理解中 , 这个智能不指向通用 , 而是指向类似人类的大脑 。
人工神经网络的“大力出奇迹”思路确实有效 , 通常更多的神经元产生更多的参数 , 而更多的参数产生更好的结果 。以GPT-3为例 , GPT-3有1750亿个参数 , 是其前身GPT-2的100倍 。
OpenAI的首席执行官Sam Altman曾在线上会议(the AC10 online meetup)表示 , 之后的GPT-5或许能够通过图灵测试 。OpenAI首席技术官Greg Brockman曾表示 , 谁拥有最大的计算机 , 谁就能获得最大的好处 。
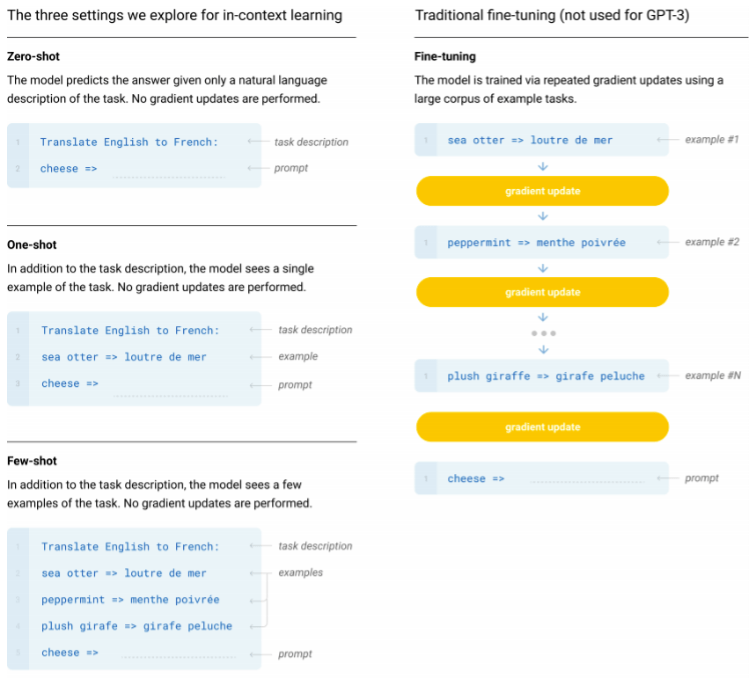
对于这次Sutskever发推文表示大型神经网络可能有点意识了 , 邱锡鹏在接受澎湃新闻(www.thepaper.cn)采访时 , 首先提及了OpenAI正在进行中的GPT-4以及GPT-3的上下文学习(In-context learning)算法 。
“GPT-3的In-context learning是一个我觉得有变革性的范式 。不再需要调参 , 给一些提示 , 就可以去做任务了 。这个目前虽然说质量并没有调参的好 , 但也能达到一个不错的效果 。这个会让大模型看起来更加智能 , 发展到一定程度它表现出某种行为 , 可能看起来像有自主意识一样 。”邱锡鹏表示 。
调参极耗费人力和时间成本 , 尤其是GPT-3这样的超大模型 。Carbontracker估计 , 训练GPT-3一次所需的电量与丹麦126户家庭每年使用的电量相同 。而In-context learning可以让一个未经进一步调参的预训练大模型 , 通过给其恰当的demonstration(示例)学会完成目标任务 。
文章图片
文章图片
“以前的方式是基于模型参数调整的 , 比如说要识别猫 , 然后看模型能不能检测到猫的位置 。如果标的不对 , 再通过误差反过来去调整参数 , 使得预测和正确位置对应起来 。上下文学习则是圈出来猫的位置 , 然后再给它一张另外的图片 , 问它猫在哪里?它就能够正确圈出来 。这个任务它之前没有见过 , 但是通过这样的方式就学会了 。”邱锡鹏讲解道 。
- 上海交大安泰学院院长:数字时代,警惕算法把你推入“思维陷阱”
- 人工智能算法可以击败ai
- 哪些打工人会被机器人替代?最新算法给你答案
- 人终究不是一种算法
- 复旦大学、中科院团队揭示东亚面部独特性遗传进化机制
- 小米11 Ultra一度霸榜DXO!影像算法获权威机构认可
- 听完411头猪哼哼 找到理解“猪语”算法
- 关掉抖音算法:广告还在,美女没了
- “算法推荐”的利弊
- 上线算法关闭键,何必遮遮掩掩?