将语言直接翻译成代码,OpenAI内测AI编码器Codex( 二 )
整个演示效果不错 , 但也暴露出了这款程序的局限性 。当前 , Codex 还没办法直接读懂人类的意思、再把每条命令转换成完美代码 。相反 , 人们需要深思熟虑再加反复试验 , 才能让它正常起效 。
也就是说 , Codex 不可能在一夜之间把业余人士变成专业程序员 , 不过它的使用门槛确实比其他编程语言更低 。
利用 GPT-3 来创建 Codex
据了解 , Codex 以 OpenAI 自家语言生成模型 GPT-3 为基础 , 这套模型使用了大量互联网素材进行训练 , 从而具备一定的文字生成与解析能力 。
稍早前 , OpenAI 的研究人员曾在一篇论文中揭示了 Codex 的详细信息 , 并解释了 OpenAI 的科学家们设法重新利用他们的旗舰语言模型 GPT-3 来创建 Codex 的过程 。
“没有免费的午餐”定理
Codex 是 GPT-3 的下一代产物 。一般来说 , 模型的学习能力随着参数的增加而增加 。GPT-3 有 1750 亿个参数 , 比它的前身 GPT-2(15 亿个参数) 多了两个数量级 。GPT-3 的训练数据集超过 600GB , 比 GPT-2 的训练数据集大 50 多倍 。
除了规模上的增长外 , GPT-3 的主要创新是“few-shot 学习” , 即执行没有经过训练的任务的能力 。
根据 OpenAI 的新论文 , 各种版本的 GPT-3 都无法解决用于评估 Codex 的编码问题 。也就是说 , GPT-3 的训练数据集中没有编码样本 , 我们不能期望它能够编码 。
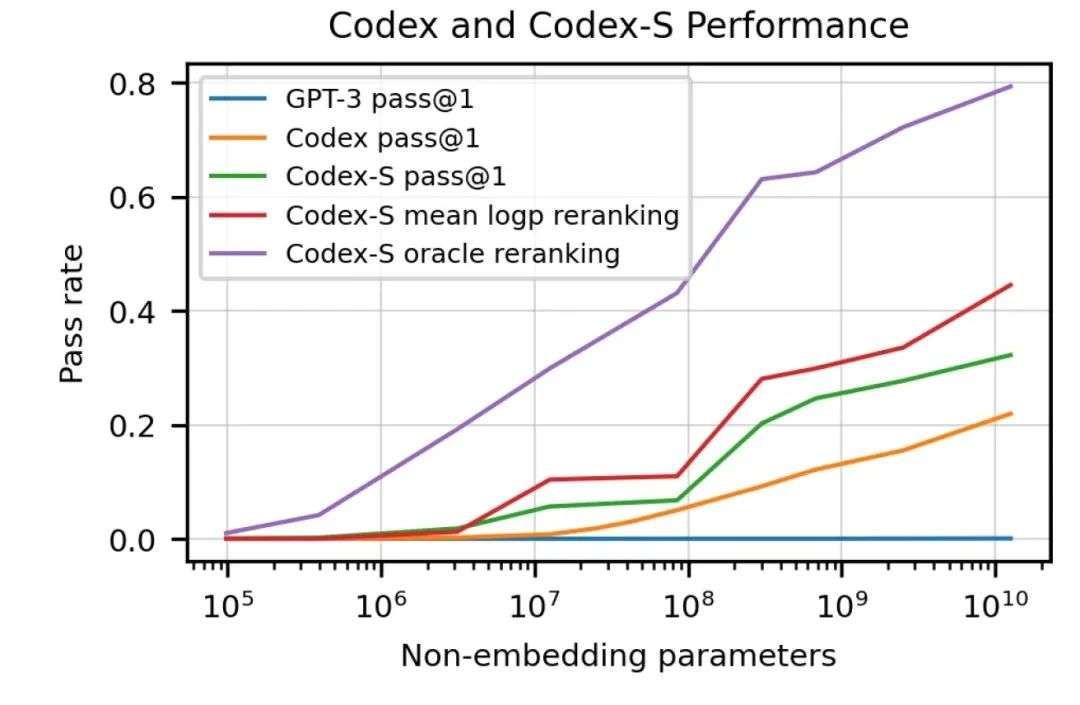
但是 , OpenAI 的科学家们也测试了 GPT-J , 一个在 the Pile 上训练的 60 亿个参数的模型 。the Pile 是一个 800GB 的数据集 , 其中包括 95GB 的 GitHub 和 32GB 的 StackExchange 数据 。GPT-J 解决了 11.4% 的编码问题 。Codex 是 GPT-3 120 亿个参数的一个版本 , 在 GitHub 的 159GB 代码示例上进行了微调 , 解决了 28.8% 的问题 。Codex 的另一个版本 Codex- s , 通过监督学习进行了优化 , 将性能提高到了 37.7%(其他 GPT 和 Codex 模型都是通过无监督学习进行训练的) 。
文章图片
文章图片
Codex 可以解决大量的编码挑战 , 使用监督学习 (Codex-S) 微调的模型版本进一步提高了性能 。
Codex 证明了机器学习仍然受制于“没有免费的午餐”定理 (NFL) , 这意味着泛化是以牺牲性能为代价的 。换句话说 , 当机器学习模型旨在解决一个特定问题时 , 它们会更加准确;另一方面 , 当他们的问题域扩大时 , 他们的表现就会下降 。
Codex 可以以较差的自然语言处理能力为代价 , 高精度地执行一项专门任务 (将功能描述和签名转换为源代码) 。另一方面 , GPT-3 是一种通用语言模型 , 它可以生成关于许多主题 (包括复杂的编程概念) 的像样的文本 , 但不能编写一行代码 。
生成与理解代码
OpenAI 的科学家们在论文中表示 , Codex“训练样本效率不高” , 并且“即使是经验丰富的开发人员 , 在他们的职业生涯中也不会遇到这么多代码” 。
【将语言直接翻译成代码,OpenAI内测AI编码器Codex】他们进一步补充说 , “一个完成了计算机科学入门课程的优秀学生 , 预计能够解决比 Codex-12B 更大比例的问题 。”“我们从 Codex 中对令牌进行抽样 , 直到遇到以下停止序列之一:' class ' ,' def ' ,' # ' ,' if ' , 或' print ' , 因为模型将继续生成其他函数或语句 。”
这意味着 Codex 将盲目地继续生成代码 , 即使它已经完成了解决提示中所述问题的部分 。
当你想要解决反复出现的简单问题时 , 这种方案非常有效 。但是当你缩小并试图编写一个大型程序来解决一个必须通过多个步骤来解决的问题时 , Codex 的局限性就变得明显了 。
- 人类与AI如何共处?诺奖科学家、将棋天才、“低欲望社会”提出者的不同解答
- 郎酒将拓宽红花郎品牌战略阵地 打造红花郎“中国节”IP
- 遍知教育赋能升级或将打破知识付费行业格局
- 2021年度中国互联网辟谣优秀作品即将发布
- “集五福”玩出新高度,云宠宝的这波黑科技营销,直接天花板了!
- 听说,这里将会有超大福利……
- 又一颗厦门卫星将遨游太空
- 华为“盘古”处理器芯片将用于pc芯片命名/代号
- cpu开盖换液金,5.1ghz下温度直接降低10度
- 摸金校尉之九幽将军安卓和苹果互通吗(摸金校尉之九幽将军安卓与ios数据互通问题讲解)